Hadoop 3.1.3集群实战安装记录
前言
大数据开发中,hadoop生态体系是大数据的核心,学习大数据开发去搭建一个简单的hadoop集群是必然的,本篇文章记录了搭建hadoop集群的步骤,好记性不如烂笔头,让我们开始吧。
先前准备
- Centos7 Linux iso镜像
- Vmware workstation虚拟机软件
- Xshell
- Hadoop3.1.3安装包
- JDK1.8
Hadoop集群架构
| 节点1 | 节点2 | 节点3 |
|---|
| IP | 192.168.110.100 | 192.168.110.101 | 192.168.110.102 |
| Hostname | hadoop001 | hadoop002 | hadoop003 |
| hadoop001 | hadoop002 | hadoop003 |
|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
简单描述一下本次搭建集群的架构,一共有三台节点,每台机器4G内存,50G存储,namenode方面使用hadoop001作为主控,hadoop003作为SecondaryNameNode冷备,hadoop002作为资源管理ResourceManager主控,3台机器作为我们的数据存储节点以及任务资源节点,做一个混合制分布式的集群。
配置虚拟机(3台虚拟机一样的配置)
- 使用Vmware安装Centos7虚拟机,默认使用最小安装,并修改静态ip和主机名
- 安装必备组件(使用root用户)
1
2
3
4
5
| yum install epel-release -y
yum install wget -y
yum install net-tools -y
yum install vim -y
yum install rsync -y
|
- 创建hadoop用户并加入到超级用户列表中(使用root用户)
1
2
3
4
5
6
7
| useradd hadoop
passwd hadoop
vim /etc/sudoers
# 添加以下内容
hadoop ALL=(ALL) NOPASSWD:ALL
|
- 创建hadoop安装文件夹(使用root用户)
1
2
| mkdir -p /opt/hadoop/module
mkdir -p /opt/hadoop/software
|
- 更改文件夹权限(使用root用户)
1
| chown -R hadoop:hadoop /opt/hadoop
|
- 上传安装包至文件夹中,并解压(使用hadoop用户)
1
2
| tar -zxvf hadoop-3.1.3.tar.gz -C /opt/hadoop/module
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/hadoop/module
|
- 配置环境变量至全局(使用root用户)
1
2
3
4
5
6
7
8
9
10
11
| vim /etc/bashrc
# 添加以下内容至文件最后
# JAVA_HOME
export JAVA_HOME=/opt/hadoop/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# HADOOP_HOME
export HADOOP_HOME=/opt/hadoop/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
|
- 配置主机名到hosts文件中
1
2
3
4
5
6
| vim /etc/hosts
# 将以下内容添加至文件中
192.168.110.100 hadoop001
192.168.110.101 hadoop002
192.168.110.102 hadoop003
|
- 配置分发脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| #
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop001 hadoop002 hadoop003
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
#
# 将以上脚本保存至/usr/bin/xsync
chmod +x /usr/bin/xsync
|
- 配置查看集群状态脚本
1
2
3
4
5
6
7
8
9
10
11
12
| #
#!/bin/bash
for i in hadoop001 hadoop002 hadoop003
do
echo "======== $i ========"
ssh $i "jps | grep -v Jps"
done
#
# 将以上脚本保存至/usr/bin/jpsall
chmod +x /usr/bin/jpsall
|
配置ssh免密
1
2
3
4
5
| # 生成 公钥+私钥
ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa
# 将本地公钥添加到授权文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
|
- 收集其他机器的公钥到一台机器的
authorized_keys中,设置600权限,并分发到其他机器上去
1
2
| chmod 600 ~/.ssh/authorized_keys
xsync ~/.ssh/authorized_keys
|
配置Hadoop集群
- 修改
$HADOOP_HOME/etc/hadoop中的core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<name>hadoop.data.dir</name>
<value>/opt/hadoop/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
|
- 修改
$HADOOP_HOME/etc/hadoop中的hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.data.dir}/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.data.dir}/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.data.dir}/namesecondary</value>
</property>
<property>
<name>dfs.client.datanode-restart.timeout</name>
<value>30</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:9868</value>
</property>
|
- 修改
$HADOOP_HOME/etc/hadoop中的yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
|
- 修改
$HADOOP_HOME/etc/hadoop中的mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
|
- 修改
$HADOOP_HOME/etc/hadoop中的workers
1
2
3
4
| # 将所有节点加入到workers
hadoop001
hadoop002
hadoop003
|
- 分发配置文件到其他节点
启动集群
- 第一次启动,格式化namenode,在hadoop001上执行:
- 启动namenode与secondary namenode,在hadoop001上执行:
- 启动resource manager,data node,node manager,在hadoop002上执行:
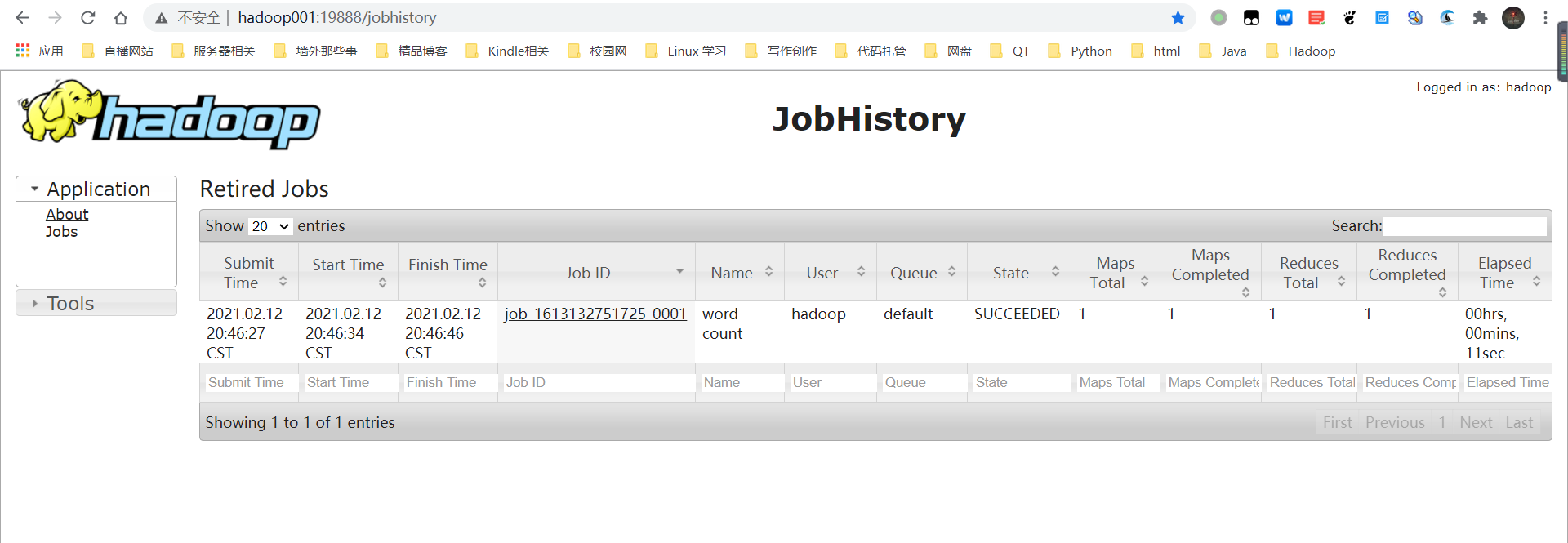
- 启动Jobhistory,在hadoop001上执行:
1
2
| mapred --daemon start historyserver
|
验证集群
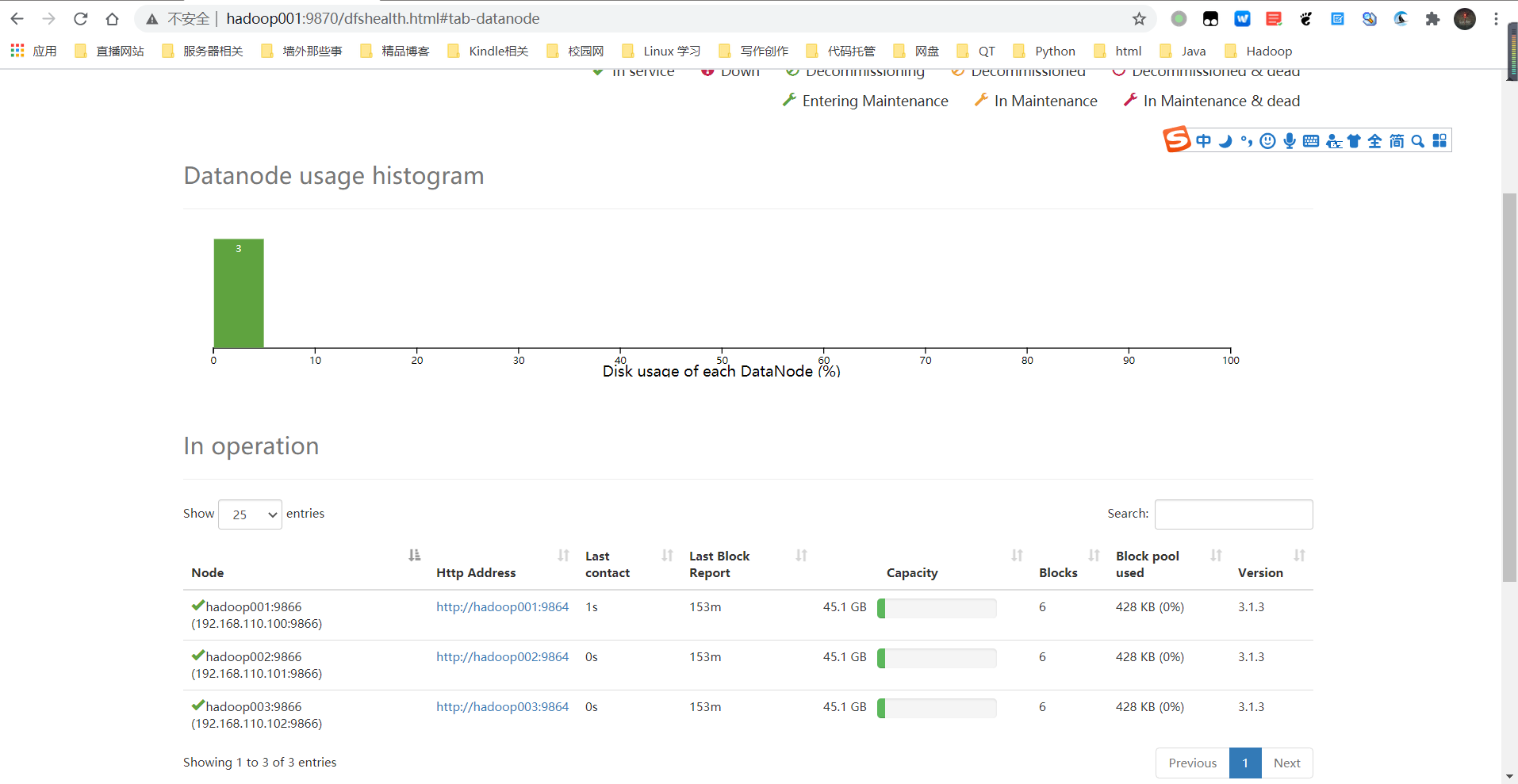
- 查看namenode页面:
http://hadoop001:9870/dfshealth.html#tab-datanode
查看resource manager页面:http://hadoop002:8088/cluster/nodes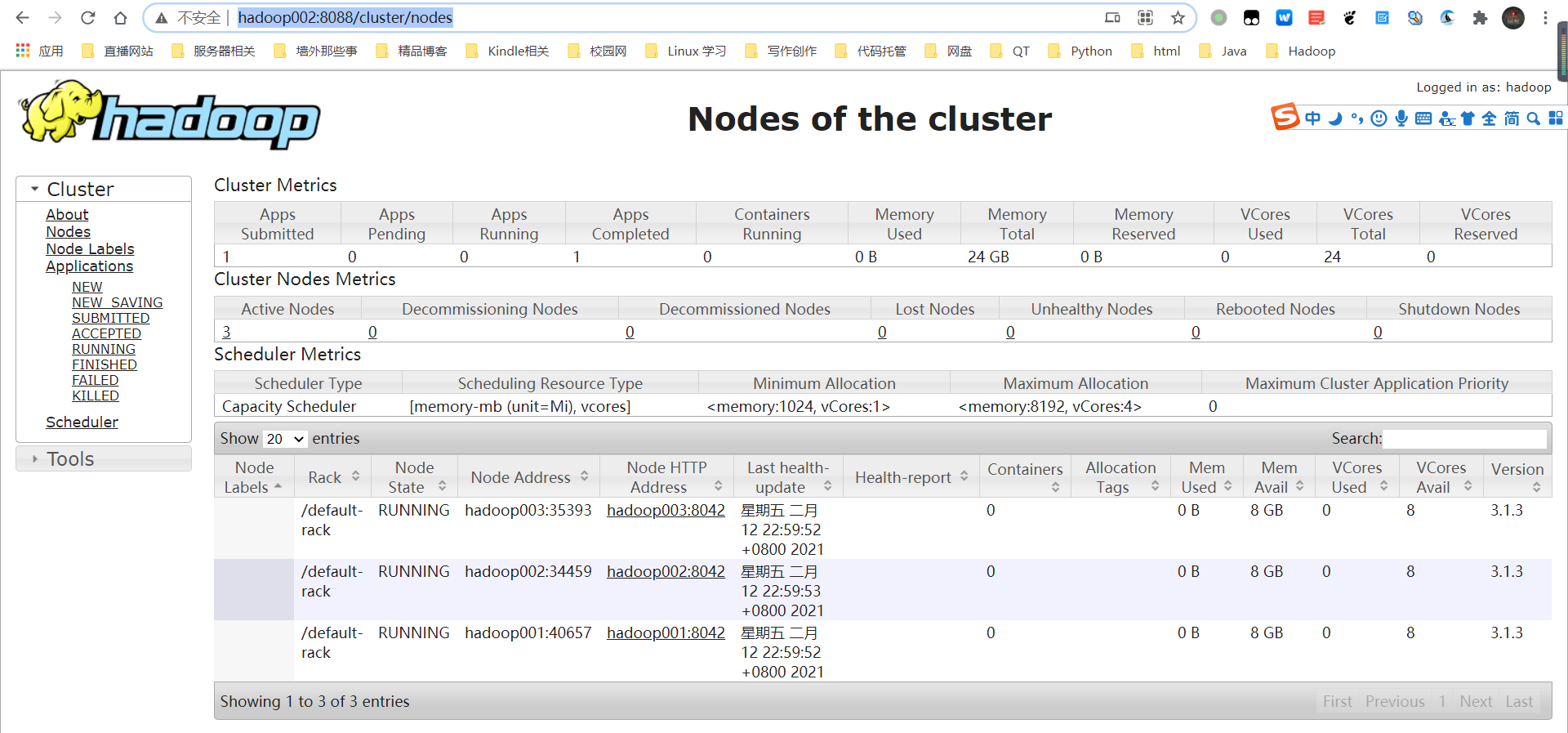
手动提交任务到hdfs,并用自带的测试jar包进行测试
1
2
3
4
| hdfs dfs -mkdir /input
hdfs dfs -put xsync.sh /input/xsync.sh
hadoop jar /opt/hadoop/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input/xsync.sh /output
hdfs dfs -ls /output
|
 wechat
wechat alipay
alipay