Fluss - 面向分析的实时流存储初探
Fluss - 面向分析的实时流存储初探
前言
在11月29日的FFA 2024上,阿里巴巴Flink团队在直播中正式开源了Fluss项目(https://github.com/alibaba/fluss) 开源过程中也出现了非常欢乐的小插曲,在访问Github的过程中遭到了神秘力量的阻拦,啼笑皆非过后,神秘的Fluss正式和大众亮相,在笔者写下这篇文章的时候,该项目的Star数量已经接近500,笔者作为大数据从业者以及开源爱好者也在下班后第一时间按照官网的quick-start教程快速体验了一把Fluss。本篇文章旨在对Fluss做一个简单的了解(通过官网)和案例展示,笔者水平有限,如有谬误,欢迎各位读者给予宝贵的建议和指正,接下来请跟随笔者的脚步,一点点揭开Fluss神秘的面纱。
Fluss - 奔腾不息的河流
Fluss 项目是由阿里云智能 Flink 团队研发的一款面向流分析的下一代流存储,旨在解决流存储在分析方面长期存在的挑战。Fluss 的项目定位是为 Apache Flink 提供实时流存储底座,进一步提升 Flink 实时流计算的能力。因此,Fluss 的名字源自“FLink Unified Streaming Storage” 的首字母缩写。在项目名字背后,还有另一层有趣的含义。Flink 项目早期起源于德国,命名自德语单词“快速”。恰巧 Fluss 也是一个德语单词,读作“弗卢斯”,意为“河流”。Fluss 虽然诞生于中国,但其名称的德语背景不仅体现了对 Flink 项目起源的一种致敬,也象征着流数据如河流般不断流动、汇聚与分发的本质。
以上内容摘自Apache Flink官方公众号文章阿里重磅开源 Fluss: Flink Unified Streaming Storage。
Flink团队对于Fluss的定位是下一代的流存储,目的是要解决在现有的流式计算架构下消息队列无法实时分析,实时点查的痛点,同时为Lakehouse架构下提供可分析的实时数据层,让数据计算更提前,数据新鲜度更高,以下是摘自官网的架构图:

从上图可以看到,Fluss替代了以往的消息队列(RMQ、KAFKA),成为数据流的载体,对接Lakehouse湖仓和实时计算引擎,同时提供了可插拔的文件写入接口,贴合云原生,实现存算分离架构,作为Flink生态的又一新成员,在初始设计上就和Flink有着非常强大的亲和性,使得Flink用户可以快速上手尝鲜。
Fluss - 核心特性(摘自官网)
- 实时读写:支持毫秒级的流式读写能力
- 列式裁剪:以列存格式存储实时流数据,通过列裁剪可提升 10 倍读取性能并降低网络成本
- 流式更新:支持大规模数据的实时流式更新。支持部分列更新,实现低成本宽表拼接
- CDC订阅:更新会生成完整的变更日志(CDC),通过 Flink 流式消费 CDC,可实现数仓全链路数据实时流动
- 实时点查:支持高性能主键点查,可作为实时加工链路的维表关联
- 湖流一体:无缝集成 Lakehouse,并为 Lakehouse 提供实时数据层。这不仅为 Lakehouse 分析带来了低延时的数据,更为流存储带来了强大的分析能力
Fluss与Flink深度集成,帮助用户构建高吞吐量、低延迟、低成本的流式数仓。
Fluss 架构概览
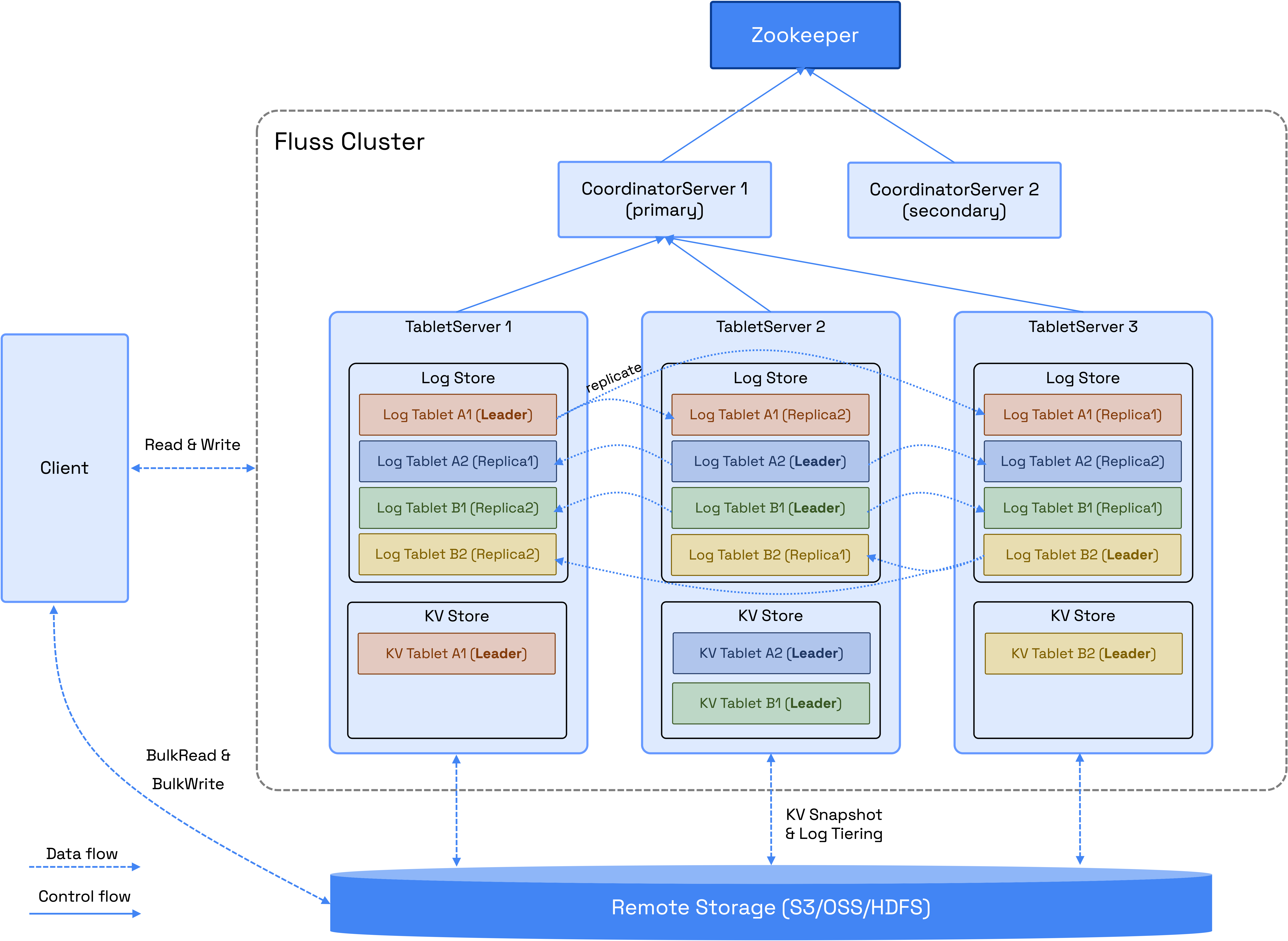
以上为Fluss官网放出的架构图,Fluss包含两个重要的角色:
CoordinatorServer
该角色充当集群的中央控制和管理组件,负责维护元数据、管理tablet分配、节点注册与发现和处理权限,同时,它也会协调关键操作,比如集群扩缩容、集群故障转移、表元数据操作等,作为整个集群的大脑,提供统一管控能力。
TableServer
该角色负责数据存储、持久化,并直接向用户提供I/O服务,由两个关键组件组成:LogStore和KvStore,对于主键表而言,LogStore和KVStore都会被使用,对于日志表而言,只有LogStore会被使用。
LogStore
LogStore旨在存储日志数据,其功能类似于数据库binlog,消息只能附加,不能修改,以确保数据完整性,其主要目的是实现低延迟流式读取,并作为预写日志(WAL)用于恢复KvStore。
KvStore
KvStore用于存储表数据,其功能类似于数据库表,支持数据更新和删除,实现了高效的查询和表管理。此外,还会生成全面的变更日志来跟踪数据修改,支持下游CDC消费。
Tablet / Bucket
根据定义的分桶策略,表数据被划分为多个bucket。
LogStore和KvStore的数据存储在Tablet中,每个tablet由一个LogTablet和一个KvTablet(可选)组成,具体取决于表是否支持更新。
LogStore和KvStore都遵循相同的bucket拆分和tablet分配策略,具有相同tablet_id的LogTablets和KvTablets总是被分配到同一TabletServer,以实现高效的数据管理,LogTablet支持基于表配置的复制因子的多个副本,确保高可用性和容错性,KvTablets不支持复制。
Fluss - 表类型
在上一章节中,简单提到了Fluss支持的表类型,目前Fluss支持两种表:
- 主键表:适用于更新场景,支持插入、更新、删除操作
- 日志表:适用于追加场景,仅支持插入操作
两种表都支持分区,唯一不同的是,主键表的分区键必须是主键的子集,来确保数据的唯一性。
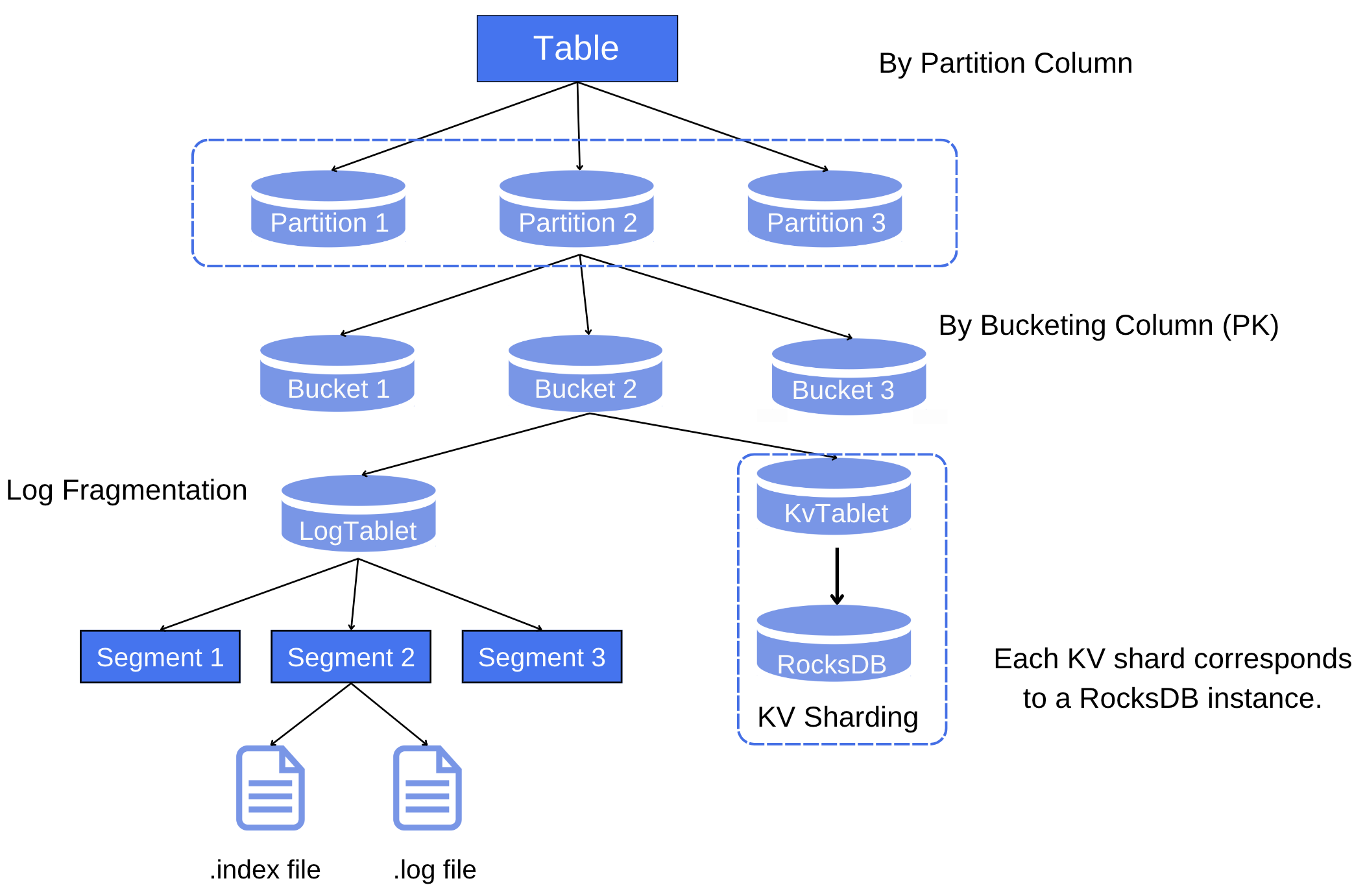
上图为每张表的文件存储结构,每张表会分成多个分区(如有分区键),每个分区下会有多个桶,每个桶会有一个LogTablet和一个KvTablet(如有主键),KvTablet是一个内嵌的RocksDB,用于加速对表的查询,LogTablet包含多个Segment,每个Segment分为索引文件和数据文件。
Fluss - 分桶策略
Fluss Table使用参数bucket.num = <num>指定分桶个数,目前Fluss支持三种分桶策略:
Hash分桶:使用指定字段hash计算进行分桶,日志表显式指定字段,主键表使用主键
使用
bucket.key = col1,col2指定hash分桶字段黏性分桶:按照批次随机选一个桶写入,随着时间推移,统计学证明数据会被均分的写入到每个桶中
使用
client.writer.bucket.no-key-assigner = stricky指定黏性分桶策略1
2
3
4
5while (newBucket < 0 || newBucket == oldBucket) {
int random = MathUtils.toPositive(ThreadLocalRandom.current().nextInt());
newBucket =
availableBuckets.get(random % availableBuckets.size()).getBucketId();
}Round-Robin分桶:简单的轮转调度算法
使用
client.writer.bucket.no-key-assigner = round_robin指定round-robin分桶策略
[!IMPORTANT]
- 主键表仅支持hash分桶策略
- 日志表支持三种分桶策略,默认使用黏性分桶
Fluss - 分区
Fluss Table支持手动创建分区和自动创建分区,分区可用于加速查询,使数据在逻辑上有效组织。
但有以下限制:
- 目前Fluss Table仅支持一个分区键,且分区键的类型必须为STRING
- 如果表类型为主键表,分区键必须是主键的子集
- 自动创建分区策略仅支持在创建表时指定,不支持在表表创建后修改自动分区策略
详细自动分区策略配置项参照官网文档:https://alibaba.github.io/fluss-docs/docs/table-design/data-distribution/partitioning/
Fluss - TTL
Fluss支持设置表ttl时间,支持自动清理表过期数据,对于日志表,ttl时间代表数据存在时间,对于主键表,ttl时间代表主键表的binlog存在时间,如果主键表想要实现类似日志表的数据自动清理,主键表需要设置自动分区策略。
Fluss - 数据类型
| DataType | Description |
|---|---|
| BOOLEAN | A boolean with a (possibly) three-valued logic of TRUE, FALSE, UNKNOWN. |
| TINYINT | A 1-byte signed integer with values from -128 to 127. |
| SMALLINT | A 2-byte signed integer with values from -32,768 to 32,767. |
| INT | A 4-byte signed integer with values from -2,147,483,648 to 2,147,483,647. |
| BIGINT | An 8-byte signed integer with values from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807. |
| FLOAT | A 4-byte single precision floating point number. |
| DOUBLE | An 8-byte double precision floating point number. |
| CHAR(n) | A fixed-length character string where n is the number of code points. n must have a value between 1 and Integer.MAX_VALUE (both inclusive). |
| STRING | A variable-length character string. |
| DECIMAL(p, s) | A decimal number with fixed precision and scale where p is the number of digits in a number (=precision) and s is the number of digits to the right of the decimal point in a number (=scale). p must have a value between 1 and 38 (both inclusive). s must have a value between 0 and p (both inclusive). |
| DATE | A date consisting of year-month-day with values ranging from 0000-01-01 to 9999-12-31. Compared to the SQL standard, the range starts at year 0000. |
| TIME | A time WITHOUT time zone with no fractional seconds by default. An instance consists of hour:minute:second with up to second precision and values ranging from 00:00:00 to 23:59:59. Compared to the SQL standard, leap seconds (23:59:60 and 23:59:61) are not supported as the semantics are closer to java.time.LocalTime. A time WITH time zone is not provided. |
| TIME§ | A time WITHOUT time zone where p is the number of digits of fractional seconds (=precision). p must have a value between 0 and 9 (both inclusive). An instance consists of hour:minute:second[.fractional] with up to nanosecond precision and values ranging from 00:00:00.000000000 to 23:59:59.999999999. Compared to the SQL standard, leap seconds (23:59:60 and 23:59:61) are not supported as the semantics are closer to java. time. LocalTime. A time WITH time zone is not provided. |
| TIMESTAMP | A timestamp WITHOUT time zone with 6 digits of fractional seconds by default. An instance consists of year-month-day hour:minute:second[.fractional] with up to microsecond precision and values ranging from 0000-01-01 00:00:00.000000 to 9999-12-31 23:59:59.999999. Compared to the SQL standard, leap seconds (23:59:60 and 23:59:61) are not supported as the semantics are closer to java. time. LocalDateTime. |
| TIMESTAMP§ | A timestamp WITHOUT time zone where p is the number of digits of fractional seconds (=precision). p must have a value between 0 and 9 (both inclusive). An instance consists of year-month-day hour:minute:second[.fractional] with up to nanosecond precision and values ranging from 0000-01-01 00:00:00.000000000 to 9999-12-31 23:59:59.999999999. Compared to the SQL standard, leap seconds (23:59:60 and 23:59:61) are not supported as the semantics are closer to java. time. LocalDateTime. |
| TIMESTAMP_LTZ | A a timestamp WITH time zone TIMESTAMP WITH TIME ZONE with 6 digits of fractional seconds by default. An instance consists of year-month-day hour:minute:second[.fractional] zone with up to microsecond precision and values ranging from 0000-01-01 00:00:00.000000 +14:59 to 9999-12-31 23:59:59.999999 -14:59. Compared to the SQL standard, leap seconds (23:59:60 and 23:59:61) are not supported as the semantics are closer to java. time. OffsetDateTime. |
| TIMESTAMP_LTZ§ | A a timestamp WITH time zone TIMESTAMP WITH TIME ZONE where p is the number of digits of fractional seconds (=precision). p must have a value between 0 and 9 (both inclusive). An instance consists of year-month-day hour:minute:second[.fractional] with up to nanosecond precision and values ranging from 0000-01-01 00:00:00.000000000 to 9999-12-31 23:59:59.999999999. Compared to the SQL standard, leap seconds (23:59:60 and 23:59:61) are not supported as the semantics are closer to java. time. LocalDateTime |
| BYTES | A variable-length binary string (=a sequence of bytes). |
Fluss - 牛刀小试
[!NOTE]
目前Fluss支持Flink 1.18、1.19、1.20
官网demo
官网提供了非常完整的demo案例,提供了一个根据订单实时join客户信息生成大宽表的场景,只需要有docker环境即可,以下为快速启动服务的docker-compose.yaml:
1 | version: '2.1' |
- 启动服务:
1 | docker-compose up -d |
1 | ┌─[tianchao.thatcher@xxxxxx] - [~/fluss-quickstart-flink] - [Fri Nov 29, 17:22] |
访问http://localhost:8083/即可访问Flink页面:

- 拉起sql-client:
1 | docker-compose exec jobmanager ./sql-client |

- 官网demo为我们预先创建了三张表:
1 | Flink SQL> show tables; |
分别是客户信息表、订单表、国家信息表:
1 | CREATE TEMPORARY TABLE `default_catalog`.`default_database`.`source_nation` ( |
- 接下来创建Fluss Catalog:
1 | CREATE CATALOG my_fluss WITH ( |

- 创建Fluss表:
1 | CREATE TABLE fluss_order ( |

- 将预先创建好的三张表数据写入到Fluss表中:
1 | EXECUTE STATEMENT SET |


- 订单信息实时enrich:
1 | INSERT INTO enriched_orders |


- ad-hoc查询:
1 | -- use tableau result mode |

- 主键查询:
1 | SELECT * FROM fluss_order where order_key = 47564032; |

1 | SELECT * FROM fluss_customer where cust_key = 19; |

- 主键表更新
1 | UPDATE fluss_customer SET `name` = 'fluss_updated' WHERE `cust_key` = 19; |

- 主键表删除
1 | DELETE FROM fluss_customer WHERE `cust_key` = 1; |

日志表写入
创建日志表
1
2
3
4
5
6CREATE TABLE log_table (
order_id BIGINT,
item_id BIGINT,
amount INT,
address STRING
);
创建Source表:
1
2
3
4
5
6CREATE TEMPORARY TABLE source (
order_id BIGINT,
item_id BIGINT,
amount INT,
address STRING
) WITH ('connector' = 'datagen');
插入数据至日志表中:
1
INSERT INTO log_table SELECT * FROM source;



Fluss - 表数据存储 & Zookeeper数据存储
为了验证官网上表结构的文件组织形式,进入到容器中查看数据:



由此可见主键表和非主键表相差了KvStore,同时,每个Segment拥有log部分以及index部分。
接下来查看Zookeeper数据存储:



zk中保存了相关的集群信息,选主信息,表的元数据信息
总结 & 未来展望
Fluss的出现让整个Lakehouse湖仓的建设有了新的玩法,试想之前消息队列中的数据可以被实时查询分析,数据新鲜度指数级上升,Fluss提出下一代流式计算的新架构,有着替代kafka的野心和宏伟蓝图,期待后续大规模落地的生产实践场景。
目前Fluss处于preview阶段,强依赖Zookeeper,Lakehouse Format仅支持Paimon,计算引擎仅支持Flink,数据类型支持还不够完善,还需要一段时间的迭代和向前演进,期待Fluss后续在开源社区发光发热,笔者也希望有机会参与到其中,贡献自己的一份力量。
社区清晰规划了向前演进的Roadmap,详情请见:https://alibaba.github.io/fluss-docs/roadmap/
结尾
此刻是凌晨3点,笔者终于肝完了整篇文章,如果觉得写的还ok的话,点个关注,谢谢各位读者老爷,晚安~
 wechat
wechat alipay
alipay