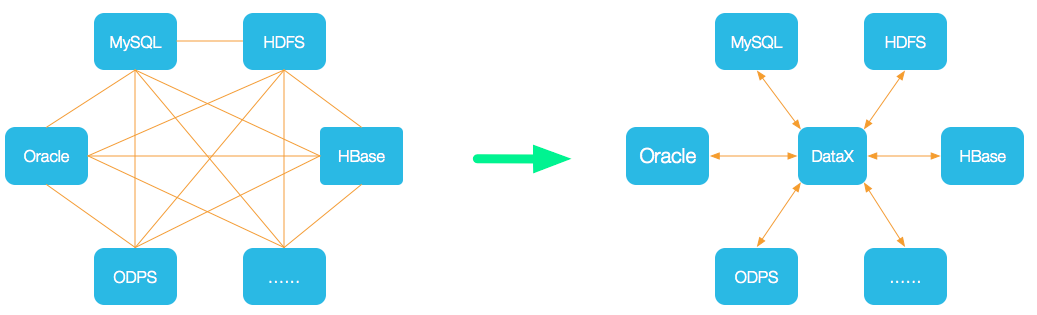
前言
书接上回,继续来聊一聊DataX源码,在上篇文章中我们已经对DataX的整体架构以及运行流程有了一个比较细致的了解,这篇文章我们将更深层次的研究DataX在调度方面的细节。
调度流程解析
确认最终任务需要的channel数量
注:channel是子任务数据传输的内存模型,后续文章将详细剖析,在这里可以暂且认为就是任务分片数量
在任务周期中含有一个split()阶段,在这个阶段做了两件事情:
- 通过配置项计算出建议的并发channel数量
- 执行reader插件中的的实际切片逻辑,并根据数量切分configuration,请注意,这一步计算出的数量可能小于第一步配置的并发数
所以在真正调度阶段,需要根据split()阶段中计算的两个值,计算出最终的channel数量
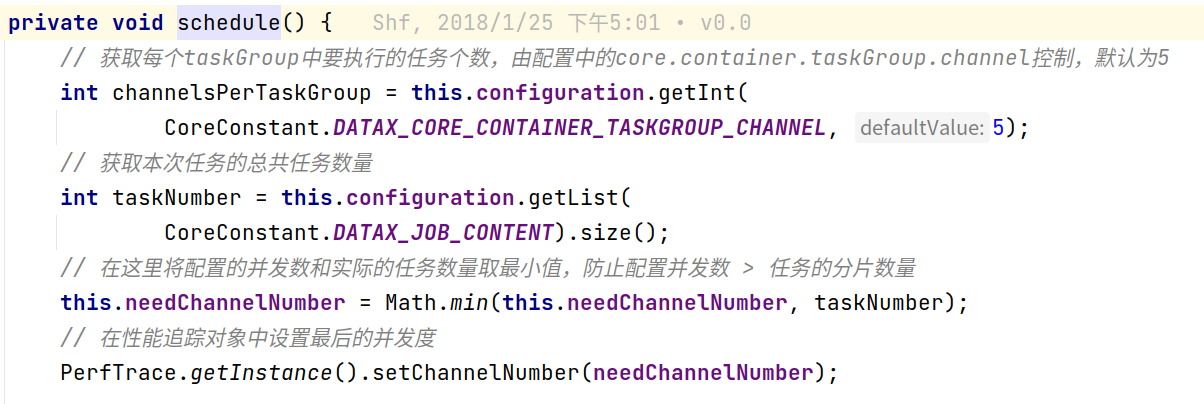
通过channel数量分配taskGroup
在计算出真正需要的channel数量之后,根据每个TaskGroup应该被分配任务的个数,计算TaskGroup的个数:

由上图可知,任务的分配是由JobAssignUtil去进行,而且从方法名称assignFairly也可以知晓,分配的逻辑是公平分配,使用的Round Robin算法,轮询分配到每个TaskGroup中,在此就简单贴一下分配的核心源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
private static List<Configuration> doAssign(LinkedHashMap<String, List<Integer>> resourceMarkAndTaskIdMap, Configuration jobConfiguration, int taskGroupNumber) {
List<Configuration> contentConfig = jobConfiguration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT);
Configuration taskGroupTemplate = jobConfiguration.clone();
taskGroupTemplate.remove(CoreConstant.DATAX_JOB_CONTENT);
List<Configuration> result = new LinkedList<Configuration>();
List<List<Configuration>> taskGroupConfigList = new ArrayList<List<Configuration>>(taskGroupNumber);
for (int i = 0; i < taskGroupNumber; i++) {
taskGroupConfigList.add(new LinkedList<Configuration>());
}
int mapValueMaxLength = -1;
List<String> resourceMarks = new ArrayList<String>();
for (Map.Entry<String, List<Integer>> entry : resourceMarkAndTaskIdMap.entrySet()) {
resourceMarks.add(entry.getKey());
if (entry.getValue().size() > mapValueMaxLength) {
mapValueMaxLength = entry.getValue().size();
}
}
int taskGroupIndex = 0;
for (int i = 0; i < mapValueMaxLength; i++) {
for (String resourceMark : resourceMarks) {
if (resourceMarkAndTaskIdMap.get(resourceMark).size() > 0) {
int taskId = resourceMarkAndTaskIdMap.get(resourceMark).get(0);
taskGroupConfigList.get(taskGroupIndex % taskGroupNumber).add(contentConfig.get(taskId));
taskGroupIndex++;
resourceMarkAndTaskIdMap.get(resourceMark).remove(0);
}
}
}
Configuration tempTaskGroupConfig;
for (int i = 0; i < taskGroupNumber; i++) {
tempTaskGroupConfig = taskGroupTemplate.clone();
tempTaskGroupConfig.set(CoreConstant.DATAX_JOB_CONTENT, taskGroupConfigList.get(i));
tempTaskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_TASKGROUP_ID, i);
result.add(tempTaskGroupConfig);
}
return result;
}
|
启动调度
ok,已经确定完了taskGroup的个数以及每个taskGroup的channel数,接下来就到了真正启动任务的环节:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
ExecuteMode executeMode = null;
AbstractScheduler scheduler;
try {
executeMode = ExecuteMode.STANDALONE;
scheduler = initStandaloneScheduler(this.configuration);
for (Configuration taskGroupConfig : taskGroupConfigs) {
taskGroupConfig.set(CoreConstant.DATAX_CORE_CONTAINER_JOB_MODE, executeMode.getValue());
}
if (executeMode == ExecuteMode.LOCAL || executeMode == ExecuteMode.DISTRIBUTE) {
if (this.jobId <= 0) {
throw DataXException.asDataXException(FrameworkErrorCode.RUNTIME_ERROR,
"在[ local | distribute ]模式下必须设置jobId,并且其值 > 0 .");
}
}
LOG.info("Running by {} Mode.", executeMode);
this.startTransferTimeStamp = System.currentTimeMillis();
scheduler.schedule(taskGroupConfigs);
this.endTransferTimeStamp = System.currentTimeMillis();
} catch (Exception e) {
LOG.error("运行scheduler 模式[{}]出错.", executeMode);
this.endTransferTimeStamp = System.currentTimeMillis();
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
this.checkLimit();
|
整个任务从scheduler.schedule(taskGroupConfigs)处被启动,在这个方法中,又调用了startAllTaskGroup(configurations):

1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Override
public void startAllTaskGroup(List<Configuration> configurations) {
this.taskGroupContainerExecutorService = Executors
.newFixedThreadPool(configurations.size());
for (Configuration taskGroupConfiguration : configurations) {
TaskGroupContainerRunner taskGroupContainerRunner = newTaskGroupContainerRunner(taskGroupConfiguration);
this.taskGroupContainerExecutorService.execute(taskGroupContainerRunner);
}
this.taskGroupContainerExecutorService.shutdown();
}
|
实际上DataX底层对于每个taskGroup都启动了一个线程TaskGroupContainerRunner,采用线程池的方式实现并发操作
调度子单位解析
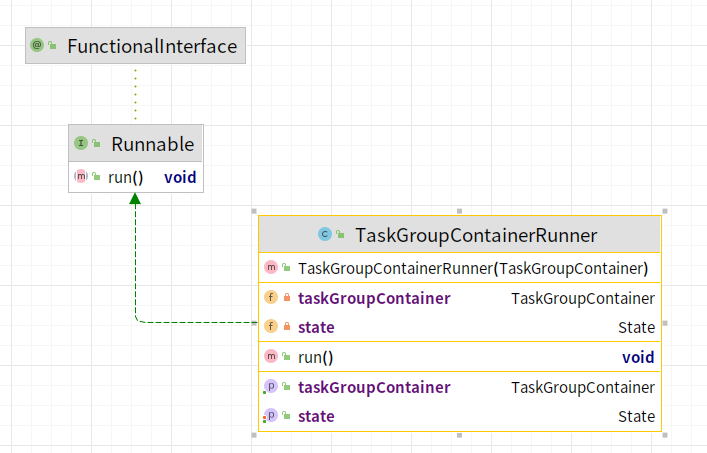
TaskGroupContainerRunner
TaskGroupContainerRunner是线程子单位,作为最上层的封装,直接提交到线程池中执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| public class TaskGroupContainerRunner implements Runnable {
private TaskGroupContainer taskGroupContainer;
private State state;
public TaskGroupContainerRunner(TaskGroupContainer taskGroup) {
this.taskGroupContainer = taskGroup;
this.state = State.SUCCEEDED;
}
@Override
public void run() {
try {
Thread.currentThread().setName(
String.format("taskGroup-%d", this.taskGroupContainer.getTaskGroupId()));
this.taskGroupContainer.start();
this.state = State.SUCCEEDED;
} catch (Throwable e) {
this.state = State.FAILED;
throw DataXException.asDataXException(
FrameworkErrorCode.RUNTIME_ERROR, e);
}
}
public TaskGroupContainer getTaskGroupContainer() {
return taskGroupContainer;
}
public State getState() {
return state;
}
public void setState(State state) {
this.state = state;
}
}
|
从代码上看,真正核心的并发子单位是TaskGroupContainer
TaskContainer
来到真正核心的TaskContainer中,这里真正启动了任务,TaskContainer主要做了以下事情:
注册task

启动task,每个子任务也就是最小的并发单位的执行器是TaskExecutor
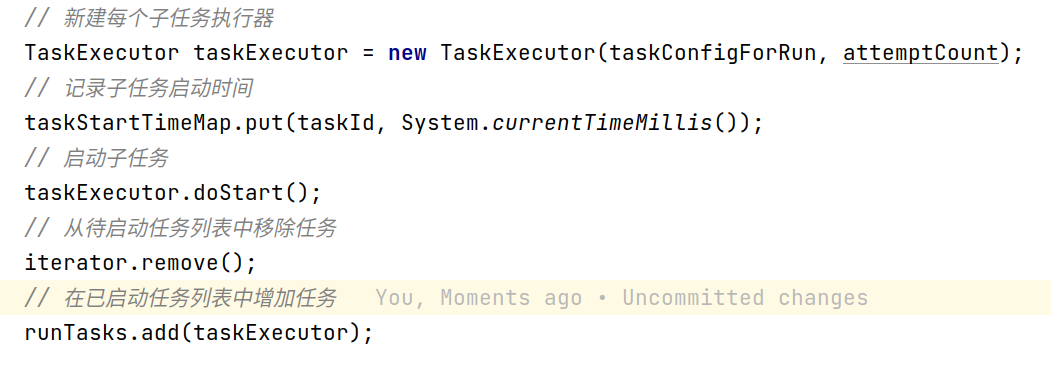
循环监控task状态,如果出现失败会进行重试

TaskExecutor
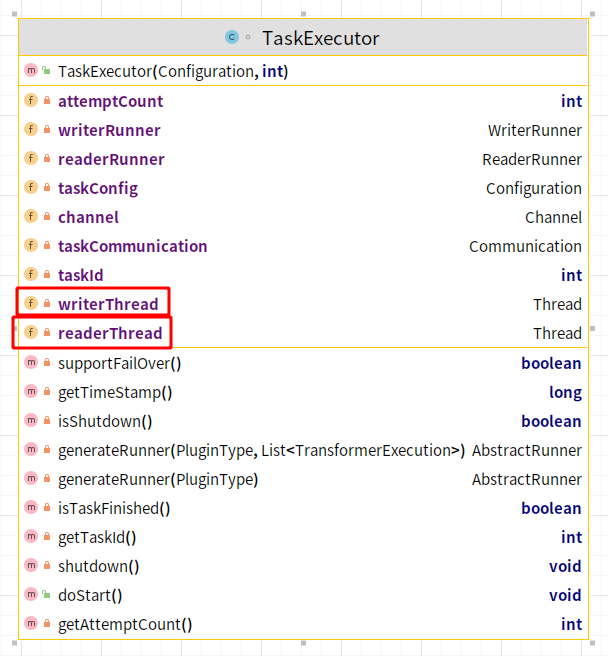
从这个类里面可以看见,做核心传输逻辑的变量是两个线程,一个写的线程,一个读的线程,在doStart方法中,启动了这两个线程:

至此,整个任务被完全启动了起来。
总结
DataX整个调度依赖于java底层线程池,它对任务进行分片后并将子任务使用Round Robin算法划分到各个任务组,以一个任务组为基本线程放进线程池并启动;同时一个子任务也包含两个线程去实现写读的流程,DataX能实现精准的流控在于它底层对分片的控制,至此,DataX的全部调度流程概括如下:
- 根据流控、并发配置确定分片数量
- 根据分片数量确定TaskGroup数量
- 通过Round Robin算法分配task至TaskGroup
- 启动TaskGroup
- 每个TaskGroup启动多个TaskExecutor
- TaskExecutor启动ReaderThread和WriterThread
下篇文章我们将聊一聊DataX的单个数据分片之间的数据传输原理,也就是TaskExecutor中的ReaderThread和WriterThread之间如何交换数据,敬请期待,我们下期再见!
 wechat
wechat alipay
alipay