Apache Seatunnel架构解析
概述
Seatunnel 是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,架构于Apache Spark 和 Apache Flink之上,开源项目地址:https://github.com/apache/incubator-seatunnel
版本演变
Seatunnel原名为Waterdrop,在更名之后正式孵化为Apache项目,同时对于两个名字也对应了不同的版本,Waterdrop指1.x版本,Seatunnel指2.x版本,对于1.x和2.x有以下区别:
| 关键功能 | 1.x | 2.x |
|---|---|---|
| 支持spark | yes | yes |
| 支持flink | no | yes |
| 主要开发语言 | scala | java |
| 主要构建工具 | sbt | maven |
为什么我们需要Seatunnel
Apache Spark和Apache Flink对于分布式数据处理和流式数据处理来说是一个伟大的进步,但较高的使用门槛让数据处理人员需要学习spark和flink复杂的运行机制和api才能够使用的更加顺畅,为降低数据处理门槛,且让spark和flink变得更加易用,减少学习成本,加快分布式数据处理在生产环境的落地,Seatunnel应运而生。
基于当前大多数数据处理工作的一些思考
- 更多的数据处理是重复的
- 数据处理的代码是冗余的
- 在数据处理工作中有一部分的比例是数据同步工作,在离线数仓计算完成之后,往往会将ads层数据同步至对查询专门优化过的OLAP数据库(ck、es等)中以提供前端报表展示的功能,这些功能是否可以沉淀?是否可以复用?
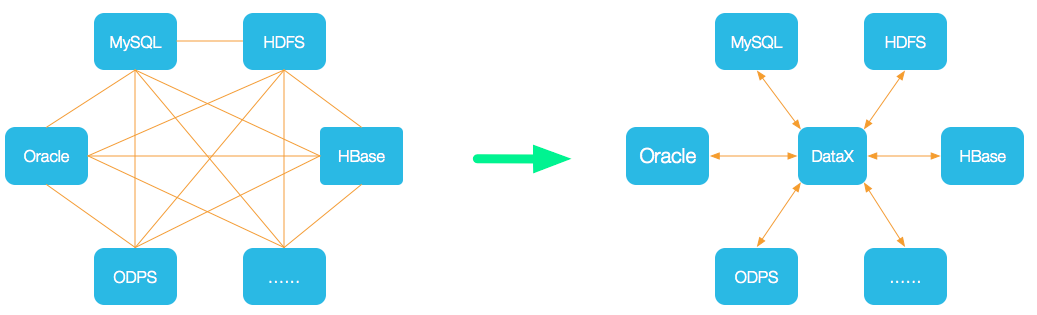
- 在数据处理过程中,可能会有多种异构数据源接入的需求,例如file、redis、hdfs、kafka、mysql….,在面对这种异构数据源集成的需求时如何去更好的应对?
- 在当前越来越多大数据框架面世的基础上,大数据处理的方向慢慢变向了sql化和低代码化,在业务看来无论底层有多少数据都会是落成一张表或是多张表,如果可以使用sql就能够计算海量数据并快速获取正确结果,对于整个业务部门对于数据的利用将更加高效
- 假设企业中需要组建数据中台,如何对外快速提供数据处理的中台能力
Seatunnel可以解决的业务痛点
- 背靠spark和flink两大分布式数据框架,天生具有分布式数据处理的能力,使业务可以更加专注于数据的价值挖掘与处理,而不是专注于底层技术对于大数据的兼容和开发
- 利用spark和flink分布式框架对于异构数据源的兼容,可以实现快速的异构数据源同步和接入
- 高度抽象业务处理逻辑,减少代码的冗余和重复开发
Seatunnel优势与缺点
优势
- 简单易用,灵活配置,无需开发
- 模块化和插件化
- 支持利用SQL做数据处理和聚合
- 由于其高度封装的计算引擎架构,可以很好的与中台进行融合,对外提供分布式计算能力
缺点
- Spark支持2.2.0 - 2.4.8,不支持spark3.x
- Flink支持1.9.0,目前flink已经迭代至1.14.x,无法向上兼容
- Spark作业虽然可以很快配置,但相关人员还需要懂一些参数的调优才能让作业效率更优
相关竞品及对比
- FlinkX,现已更名为chunjun
- StreamX
- DataX
| 关键功能 | Seatunnel | FlinkX | StreamX | DataX |
|---|---|---|---|---|
| spark是否支持 | yes | no | yes | no |
| flink是否支持 | yes,高版本兼容性不好 | yes,高版本兼容性不好 | yes,高版本兼容性好 | no |
| 部署难度 | 轻松 | 中等 | 较难 | 容易 |
| 主要功能对比 | etl、数据同步 | 数据同步 | flink任务可视化部署 | 数据同步 |
Seatunnel核心理念与内核原理
核心概念
整个Seatunnel设计的核心是利用设计模式中的“控制翻转”或者叫“依赖注入”,主要概括为以下两点:
- 上层不依赖底层,两者都依赖抽象
- 流程代码与业务逻辑应该分离
对于整个数据处理过程,大致可以分为以下几个流程:
输入->转换->输出,对于更复杂的数据处理,实质上也是这几种行为的组合:

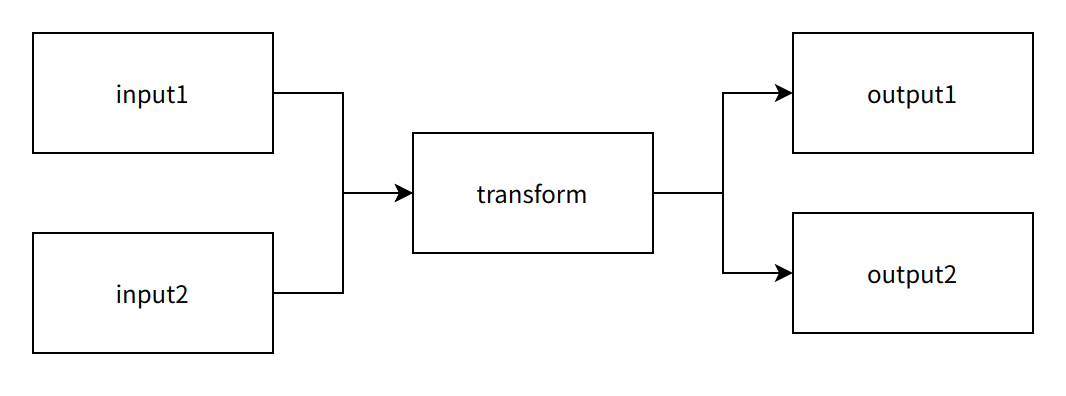
Seatunnel对于这几种数据处理的行为进行高度的抽象,在基于这层比较完善的抽象之上,对业务数据处理过程中的80%重复操作进行沉淀,做成可热插拔的插件,这样业务处理逻辑与整个数据处理实现了解耦,让用户更专注于业务的落地与实施。
内核原理
- 插件的动态注册使用了java spi技术,保证了框架的灵活扩展,设计思路参考了presto、es等,有兴趣的同学可以下去自行研究,es使用了google guice,presto使用的就是上面提到的java spi
- 在以上理论基础上,数据的转换需要做一个统一的抽象与转化,很契合的是spark或者flink都已经为我们做好了这个工作,spark的DataSet,flink的DataSet、DataStream都已经是对接入数据的一个高度抽象,本质上对数据的处理就是对这些数据结构的转换,同时这些数据在接入进来之后可以注册成上下文中的表,基于表就可以使用SQL进行处理
- 整个Seatunnel通过配置文件生成的是一个spark job或者flink job
- 技术栈包括以下:
- Java
- Scala
- Flink
- Spark
- Java spi
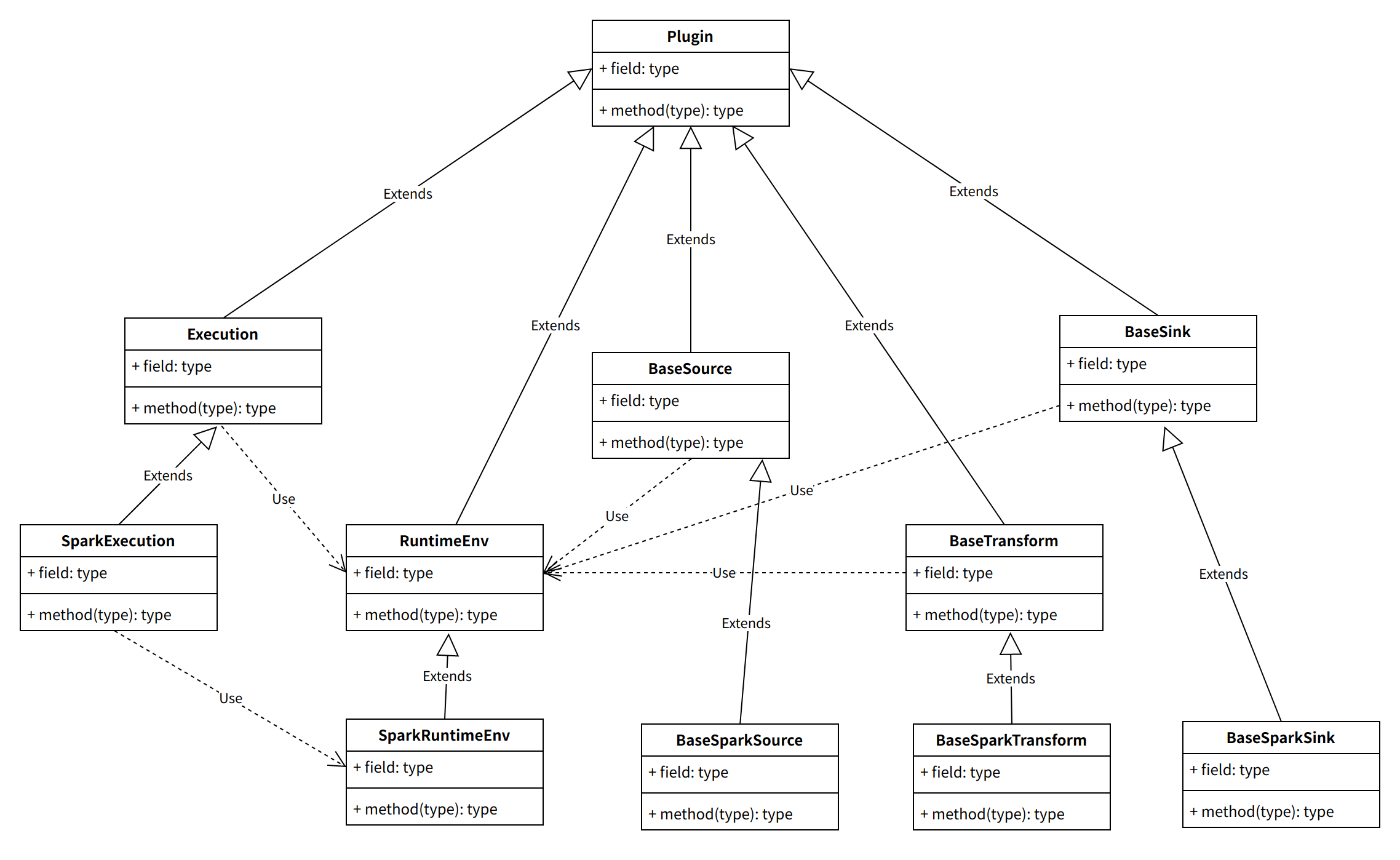
Spark插件体系架构设计
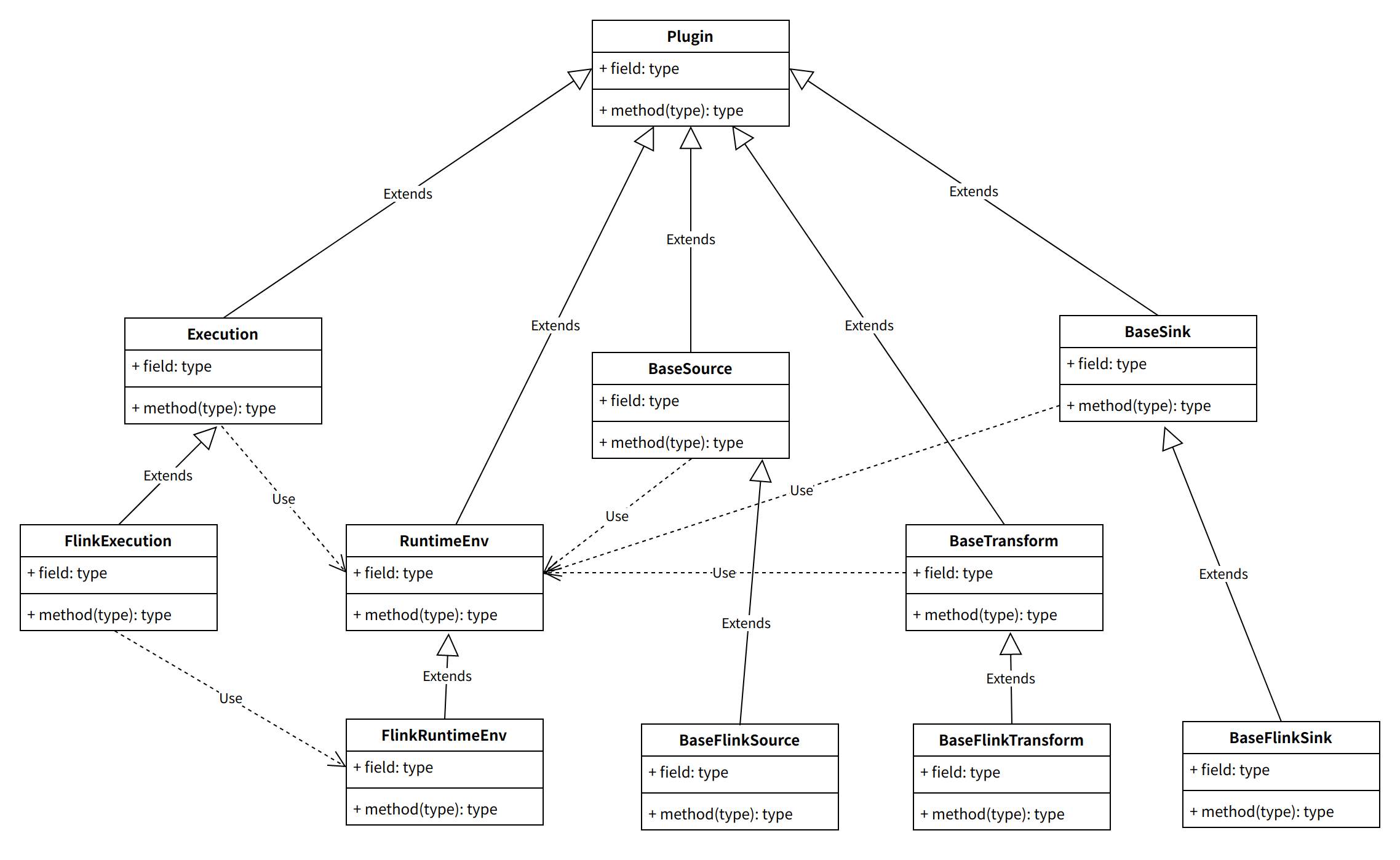
Flink插件体系架构设计
程序执行流程

最上层插件抽象实现细节
1 | public interface Plugin<T> extends Serializable { |
Spark插件上层抽象实现细节
批处理Batch
Source
1 | trait BaseSparkSource[Data] extends BaseSource[SparkEnvironment] { |
Transform
1 | trait BaseSparkTransform extends BaseTransform[SparkEnvironment] { |
Output
1 | trait BaseSparkSink[OUT] extends BaseSink[SparkEnvironment] { |
流处理Stream
1 | trait SparkStreamingSource[T] extends BaseSparkSource[DStream[T]] { |
Flink插件上层抽象实现细节
批处理Batch
Source
1 | public interface FlinkBatchSource<T> extends BaseFlinkSource { |
Transform
1 | public interface FlinkBatchTransform<IN, OUT> extends BaseFlinkTransform { |
Output
1 | public interface FlinkBatchSink<IN, OUT> extends BaseFlinkSink { |
流处理Stream
Source
1 | public interface FlinkStreamSource<T> extends BaseFlinkSource { |
Transform
1 | public interface FlinkStreamTransform<IN, OUT> extends BaseFlinkTransform { |
Output
1 | public interface FlinkStreamSink<IN, OUT> extends BaseFlinkSink { |
自定义插件步骤
- 针对不同的框架和插件类型继承对应的接口,接口中的核心处理方法
- 在java spi中注册
- 将自己定义的jar包放在Seatunnel主jar包的plugins目录下
Java spi原理解析
概念
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件,SPI的作用就是为这些被扩展的API寻找服务实现
API和SPI的区别
API-(Application Programming Interface)大多数情况下,都是实现方制定接口并完成对接口的实现,调用方仅仅依赖接口调用,且无权选择不同实现。 从使用人员上来说,API 直接被应用开发人员使用,SPI-(Service Provider Interface)是调用方来制定接口规范,提供给外部来实现调用方选择自己需要的外部实现。 从使用人员上来说,SPI 被框架扩展人员使用
实现demo
定义接口
1
2
3
4
5package com.tyrantlucifer;
public interface Animal {
void shut();
}定义main函数,使用service loader进行动态加载
1
2
3
4
5
6
7
8
9
10
11
12package com.tyrantlucifer;
import java.util.ServiceLoader;
public class Main {
public static void main(String[] args) {
ServiceLoader<Animal> services = ServiceLoader.load(Animal.class);
for (Animal service : services) {
service.shut();
}
}
}实现接口
1
2
3
4
5
6
7package com.tyrantlucifer;
public class Cat implements Animal {
public void shut() {
System.out.println("cat shut miao miao!!!");
}
}1
2
3
4
5
6
7package com.tyrantlucifer;
public class Dog implements Animal{
public void shut() {
System.out.println("dog shut wang wang!!!");
}
}注册spi,需要在resources/META-INF/services下新建以接口全类名的文件,比如我们这次的接口
com.tyrantlucifer.Animal,那么就新建一个com.tyrantlucifer.Animal文件,并在文件中添加自己的实现类: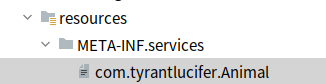
1
2com.tyrantlucifer.Cat
com.tyrantlucifer.Dog
Seatunnel demo演示
Spark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20spark {
spark.streaming.batchDuration = 5
spark.app.name = "seatunnel"
spark.ui.port = 13000
}
input {
socketStream {}
}
filter {
split {
fields = ["msg", "name"]
delimiter = ","
}
}
output {
stdout {}
}Flink
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24env {
execution.parallelism = 1
}
source {
SocketStream{
result_table_name = "fake"
field_name = "info"
}
}
transform {
Split{
separator = "#"
fields = ["name","age"]
}
sql {
sql = "select * from (select info,split(info) as info_row from fake) t1"
}
}
sink {
ConsoleSink {}
}自定义插件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68class MyStdout extends BaseOutput {
var config: Config = ConfigFactory.empty()
/**
* Set Config.
* */
override def setConfig(config: Config): Unit = {
this.config = config
}
/**
* Get Config.
* */
override def getConfig(): Config = {
this.config
}
override def checkConfig(): (Boolean, String) = {
if (!config.hasPath("limit") || (config.hasPath("limit") && config.getInt("limit") >= -1)) {
(true, "")
} else {
(false, "please specify [limit] as Number[-1, " + Int.MaxValue + "]")
}
}
override def prepare(spark: SparkSession): Unit = {
super.prepare(spark)
val defaultConfig = ConfigFactory.parseMap(
Map(
"limit" -> 100,
"format" -> "plain" // plain | json | schema
)
)
config = config.withFallback(defaultConfig)
}
override def process(df: Dataset[Row]): Unit = {
val limit = config.getInt("limit")
var format = config.getString("format")
if (config.hasPath("serializer")) {
format = config.getString("serializer")
}
format match {
case "plain" => {
if (limit == -1) {
df.show(Int.MaxValue, false)
} else if (limit > 0) {
df.show(limit, false)
}
}
case "json" => {
if (limit == -1) {
df.toJSON.take(Int.MaxValue).foreach(s => println(s))
} else if (limit > 0) {
df.toJSON.take(limit).foreach(s => println(s))
}
}
case "schema" => {
df.printSchema()
}
}
}
}
Q&A
 wechat
wechat alipay
alipay