DataX源码解析-整体架构
前言
近期在工作中需要用到DataX去作为公司内部的数据同步引擎,特花了一些时间研究了DataX的整体架构和设计思想,从中吸收了很多优秀的设计思路,作为一款纯Java实现的数据同步工具,相对于市面上已存在的基于大数据框架为背景的数据同步工具有着易部署、易扩展的优点,但不足的地方是alibaba只是开源了DataX单机模式代码,并未开源分布式部分代码,目前在Github中的只是阉割版是DataX,对此我表示很遗憾。
DataX简介
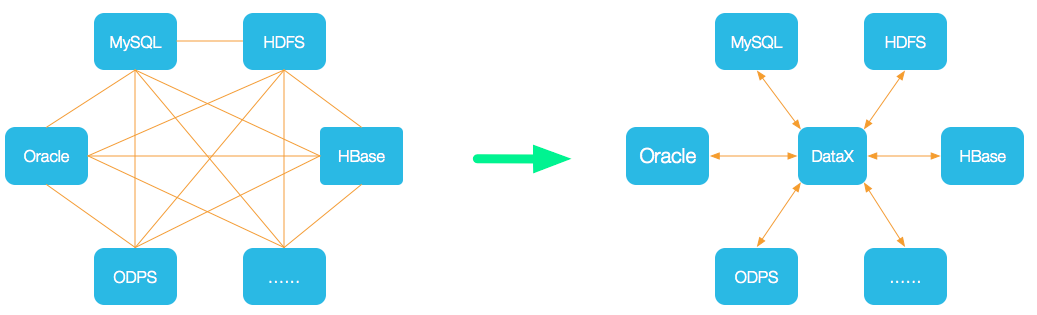
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能,项目地址:https://github.com/alibaba/DataX
以上摘抄自DataX项目首页README
架构浅析
数据统一抽象
DataX作为一款高性能的异构数据源同步工具,要解决的第一个难点是异构数据基本单位的统一抽象,为此,DataX将每一条数据全部抽象为Record,每一条Record中包含了多个Column,具体代码实现如下:
Record.java
1 | // 数据抽象接口,一条数据将具有以下特性 |
Column.java
1 | // 列抽象类 |
在基于这一层抽象的基础上,DataX对于Record有三种不同的实现,分别是:
- DefaultRecord:异构数据源传输时的成功记录

- DirtyRecord:异构数据源之间传输时的失败记录,特指脏数据
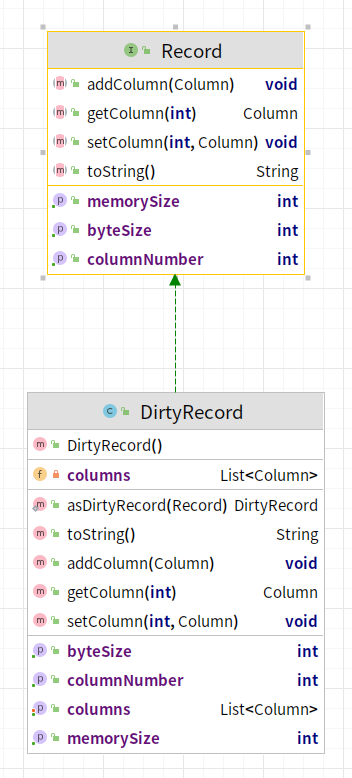
- TerminateRecord:标识传输终止的记录
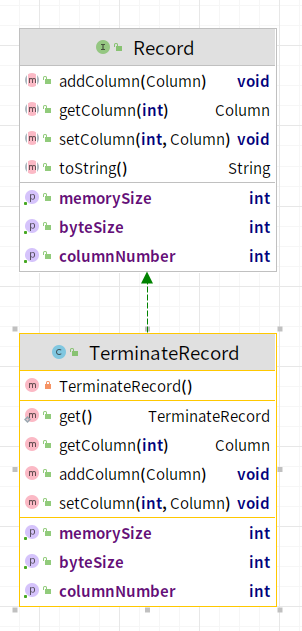
以上便是DataX中基本的传输子单位,无论是reader插件和writer插件都是将原始数据源的每一条数据转换成为以上的对象。
程序入口
在了解完DataX中基本的传输单位,接下来去看一看一个DataX任务究竟是怎样的一个流程被启动起来的,从官网得知,要启动一个简单的数据任务,要经历以下二步:
配置任务json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 1,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}使用DataX自带的Python脚本启动任务
1
python datax.py job.json
在扒了datax.py的源码之后,发现使用python去进行启动的作用是快速构建了DataX的启动命令,尤其是补充了一些有用的jvm参数,实际上最后python拼接出来的命令如下:
1 | java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/log -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/log -Dloglevel=info -Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener -Djava.security.egd=file:///dev/urandom -Ddatax.home=/home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax -Dlogback.configurationFile=/home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/conf/logback.xml -classpath /home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/lib/*:. -Dlog.file.name=b_stream2stream_json com.alibaba.datax.core.Engine -mode standalone -jobid -1 -job /home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/job/stream2stream.json |
我们根据这条命令就会发现入口的主类:com.alibaba.datax.core.Engine
主程序执行流程

由上图可知,一切的一切都是从Engine.entry(args)这个方法开始,接下来分析一下这个方法究竟做了哪些工作:
解析命令行参数:
- job:job json路径
- jobid:当前job的id,如果用户未显式指定,那么将会被置为-1
- mode:当前job的运行模式,当前DataX开源版本只支持Standalone模式
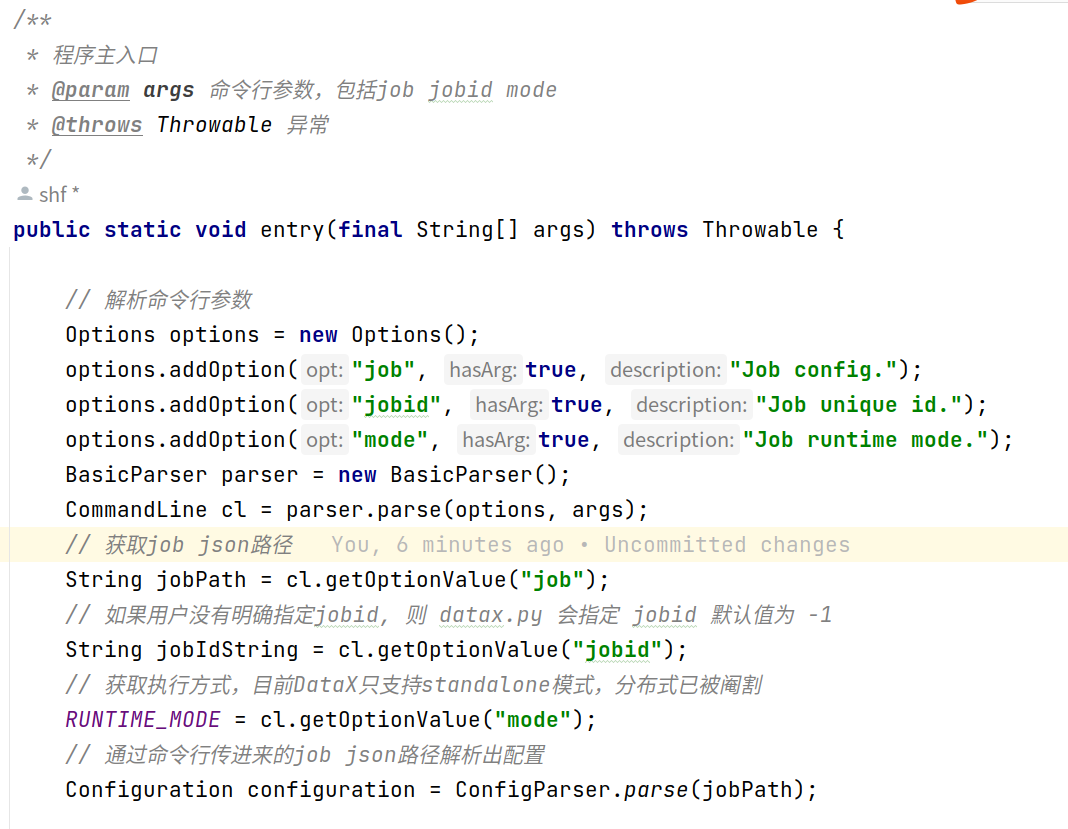
解析配置,
ConfigParser.parse(jobPath),往配置中加入系统默认项,用户只提供job部分,补上其余commoncoreentryjobplugin配置项1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123{
"common": {
"column": {
"dateFormat": "yyyy-MM-dd",
"datetimeFormat": "yyyy-MM-dd HH:mm:ss",
"encoding": "utf-8",
"extraFormats": [
"yyyyMMdd"
],
"timeFormat": "HH:mm:ss",
"timeZone": "GMT+8"
}
},
"core": {
"container": {
"job": {
"id": -1,
"reportInterval": 10000
},
"taskGroup": {
"channel": 5
},
"trace": {
"enable": "false"
}
},
"dataXServer": {
"address": "http://localhost:7001/api",
"reportDataxLog": false,
"reportPerfLog": false,
"timeout": 10000
},
"statistics": {
"collector": {
"plugin": {
"maxDirtyNumber": 10,
"taskClass": "com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector"
}
}
},
"transport": {
"channel": {
"byteCapacity": 67108864,
"capacity": 512,
"class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
"flowControlInterval": 20,
"speed": {
"byte": -1,
"record": -1
}
},
"exchanger": {
"bufferSize": 32,
"class": "com.alibaba.datax.core.plugin.BufferedRecordExchanger"
}
}
},
"entry": {
"jvm": "-Xms1G -Xmx1G"
},
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,你好,世界-DataX"
}
],
"sliceRecordCount": 10
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
},
"plugin": {
"reader": {
"streamreader": {
"class": "com.alibaba.datax.plugin.reader.streamreader.StreamReader",
"description": {
"mechanism": "use datax framework to transport data from stream.",
"useScene": "only for developer test.",
"warn": "Never use it in your real job."
},
"developer": "alibaba",
"name": "streamreader",
"path": "/home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/plugin/reader/streamreader"
}
},
"writer": {
"streamwriter": {
"class": "com.alibaba.datax.plugin.writer.streamwriter.StreamWriter",
"description": {
"mechanism": "use datax framework to transport data to stream.",
"useScene": "only for developer test.",
"warn": "Never use it in your real job."
},
"developer": "alibaba",
"name": "streamwriter",
"path": "/home/tyrantlucifer/IdeaProjects/DataX/target/datax/datax/plugin/writer/streamwriter"
}
}
}
}打印当前jvm虚拟机信息

打印当前配置

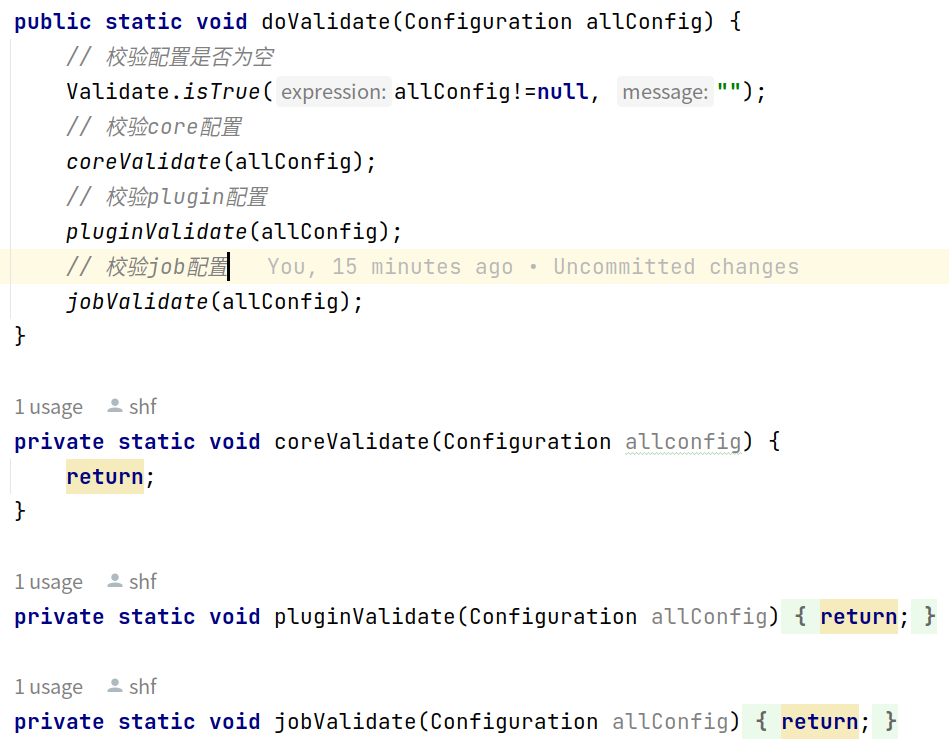
配置校验,认真同学们会发现,阿里在这块还是有点敷衍的,直接给return,毫无一丝校验的逻辑,我怀疑是配置校验涉及到了阿里某些不想开源的模块,所以直接阉割,手动狗头:
启动任务

任务执行流程
此时程序进入到了Engine.start(configuration)的执行流程,在这一步中经历以下环节:
绑定Column转换格式,这一步会在配置中指定以下信息:
- 字符串转换格式
- 日期转换格式
- 字节编码格式

初始化PluginLoader,PluginLoader可以理解是所有数据同步插件的统一加载器,在这一步中实际上是任务将当前的任务配置赋值给了PluginLoader一份:

实例化任务容器,判断配置中
core.container.model是job还是jobGroup,如果是job,那么实例化JobContainer,如果是jobGroup实例化TaskGroupContainer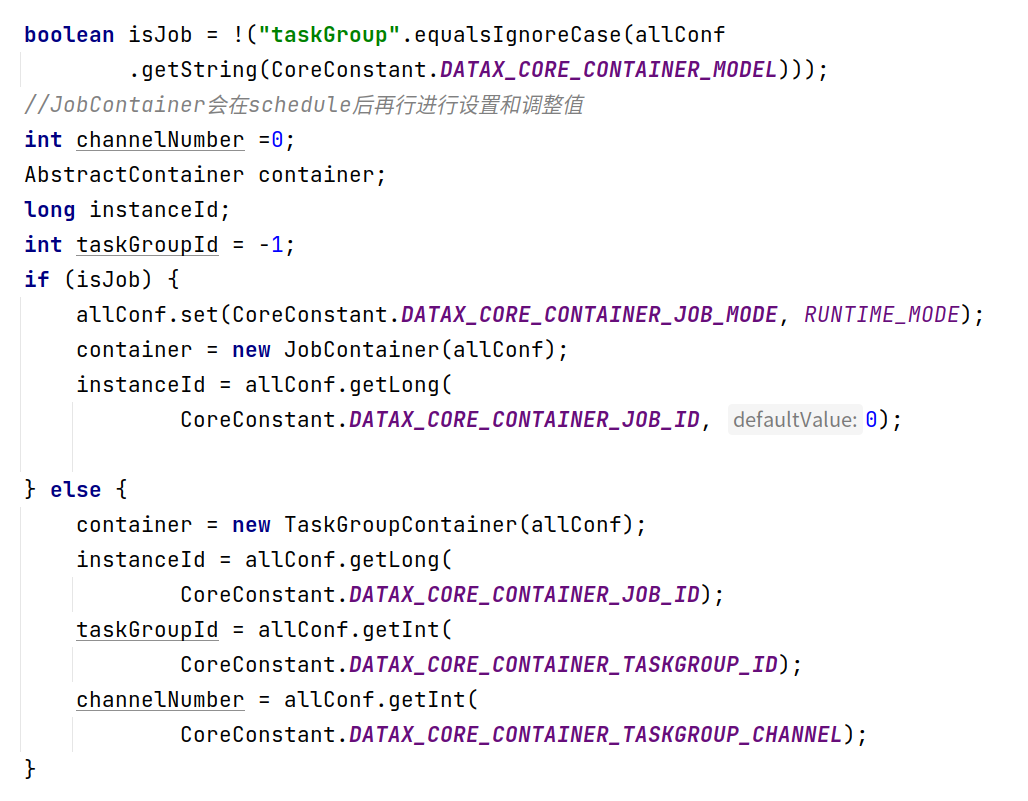
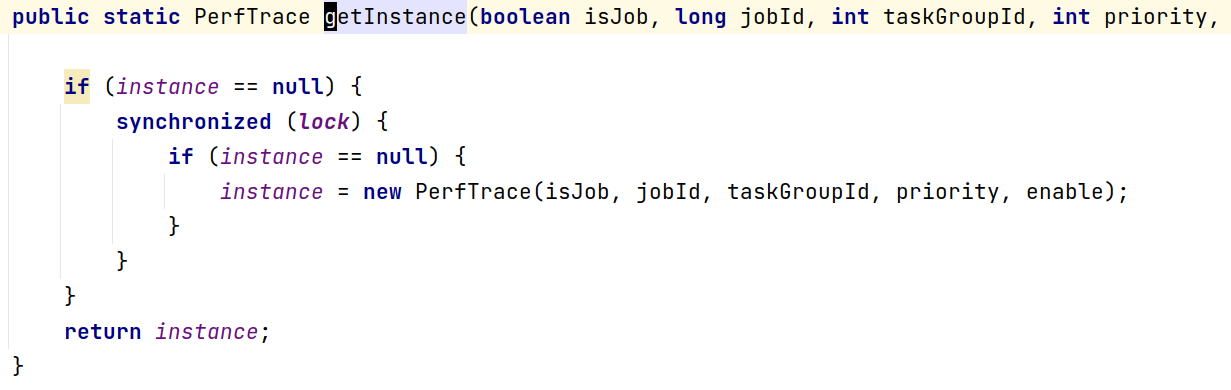
初始化性能追踪器,使用单例模式,一个jvm进程中只存在一个PerfTrace

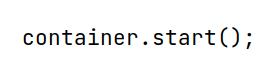
启动第3步实例化好的任务容器
任务容器执行流程
任务容器被启动后,会执行任务生命周期的每一个阶段
- preHandle:用户可配置任务处理前的前置处理逻辑,这个前置处理逻辑处于writer或者reader中
- init:任务初始化阶段,初始化reader和writer(使用自定义的classLoader进行类加载),调用reader和writer的init()方法
- prepare:任务准备阶段,实际上调用reader和writer的prepare()方法
- split:任务分片,调整channel数,其实也就是任务的并发数
- 调整channel数量
- 判断是否设置了字节限制
job.setting.speed.byte,如果是,根据字节限制配置计算channel数量 - 判断是否设置了条数限制
job.setting.speed.record,如果是,根据条数限制配置计算channel数量 - 取以上1 2步的最小值
- 如果1 2步都没有设置,取配置中的
job.setting.speed.channel来确定channel数量
- 判断是否设置了字节限制
- 根据channel数量切分configuration,包括readerConfig和writerConfig,切分逻辑在每个插件中具体实现的,在切分好配置之后会将配置覆盖进
job.content中
- 调整channel数量
- schedule:任务调度执行阶段,根据第四步中确定的并发数进行任务调度工作
- 根据上面的split中算出的channel数,设置taskGroup的数量,默认一个taskGroup中运行5个channel,切分configuration,为每个taskGroup创建自己的configuration
- 开始对taskGroupConfigurations进行调度,底层使用线程池,通过taskGroup的数量来确定线程池的线程个数
- 启动线程,TaskGroupContainerRunner,每一个TaskGroupContainerRunner中包含了一个TaskGroupContainer,实际上执行任务核心逻辑的容器是TaskGroupContainer,TaskGroupContainer会为每个channel创建TaskExecutor,TaskExecutor是执行子任务的最小单位
- while循环监控taskGroup运行状态,等待每个子任务完成和数据情况的上报,并收集
- post:任务执行结束后阶段
- 还原线程上下文类加载器
- 调用writer和reader的post方法
- postHandler:任务结束后后置处理逻辑,这个后置处理逻辑处于writer或者reader中
- invokeHooks:DataX预留的spi接口,用户可自定义spi插件来丰富整个同步任务的生命周期
实际上我认为如果是一个数据任务执行的话,1和6阶段完全不必要存在,但是如果是任务之间DAG调度,这两个阶段就可以派上用场,是否阿里在这里阉割了DAG调度的功能,咱也不知道,就在这瞎猜猜而已

总结
从代码逻辑上看,DataX的代码流程是比较清晰且设计思路明确的,之所以它能够实现高效的异构数据源同步工作,总共实现了以下这么几点:
- 实现了对数据的统一抽象
- 实现了对作业生命周期的分割和管理
- 实现了对作业的切片与任务的并发
- 实现了对作业的全流程监控
下篇文章将对DataX的调度流程做一个详细的剖析,敬请期待,我们下期再见!
 wechat
wechat alipay
alipay