DataX源码解析-数据传输
前言 书接上回,继续来聊一聊DataX源码,在上篇文章中我们已经对于DataX的调度流程进行了细致的剖析,这篇文章我们将更深层次的研究DataX在数据传输与交换方面的细节。 简单回顾 上文提到,DataX核心运行子单位是TaskExecutor,一个TaskExecutor中会拥有两个线程,分别是WriterThread和ReaderThread,这两个线程承担着整个数据传输的重任,所以今天整篇文章的重点将围绕这两个线程展开,如果读者阅读至此觉得概念晦涩难懂,请移步我之前的两篇文章去先了解一下整个DataX的原理和架构: DataX整体架构 DataX调度流程 线程的创建 来到TaskGroupContainer源码中,找到TaskExecutor新建WriterThread和ReaderThread的地方: 1234567891011// 生成WriterThreadwriterRunner = (WriterRunner) generateRunner(PluginType.WRITER);this.writerThread = new Thread(writerRunner, ...

数据结构系列35-快速排序
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253/************************************************************************** File Name: quickSort.c* Author: TyrantLucifer* E-mail: TyrantLucifer@gmail.com* Blog: https://tyrantlucifer.com* Created Time: Sun 10 Apr 2022 02:29:02 PM CST ************************************************************************/#include <stdio.h>void printArray(int array[], int length) { for (int i = 0; ...
数据结构系列34-冒泡排序
1234567891011121314151617181920212223242526272829303132333435/************************************************************************** File Name: bubbleSort.c* Author: TyrantLucifer* E-mail: TyrantLucifer@gmail.com* Blog: https://tyrantlucifer.com* Created Time: Mon 04 Apr 2022 06:01:03 PM CST ************************************************************************/#include <stdio.h>void printArray(int array[], int length) { for (int i = 0; i < length; i++) { ...
数据结构系列33-希尔排序
123456789101112131415161718192021222324252627282930313233343536373839404142/************************************************************************** File Name: shellSort.c* Author: TyrantLucifer* E-mail: TyrantLucifer@gmail.com* Blog: https://tyrantlucifer.com* Created Time: Sun 03 Apr 2022 06:50:27 PM CST ************************************************************************/#include <stdio.h>void printArray(int array[], int length) { for (int i = 0; i < length; i++) & ...

Apache Seatunnel架构解析
概述 Seatunnel 是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,架构于Apache Spark 和 Apache Flink之上,开源项目地址:https://github.com/apache/incubator-seatunnel 版本演变 Seatunnel原名为Waterdrop,在更名之后正式孵化为Apache项目,同时对于两个名字也对应了不同的版本,Waterdrop指1.x版本,Seatunnel指2.x版本,对于1.x和2.x有以下区别: 关键功能 1.x 2.x 支持spark yes yes 支持flink no yes 主要开发语言 scala java 主要构建工具 sbt maven 为什么我们需要Seatunnel Apache Spark和Apache Flink对于分布式数据处理和流式数据处理来说是一个伟大的进步,但较高的使用门槛让数据处理人员需要学习spark和flink复杂的运行机制和api才能够使用的更加顺畅,为降低数据处理门槛,且让spark和flink变得更加易用,减少学习成本,加快 ...
DataX源码解析-调度流程
前言 书接上回,继续来聊一聊DataX源码,在上篇文章中我们已经对DataX的整体架构以及运行流程有了一个比较细致的了解,这篇文章我们将更深层次的研究DataX在调度方面的细节。 调度流程解析 确认最终任务需要的channel数量 注:channel是子任务数据传输的内存模型,后续文章将详细剖析,在这里可以暂且认为就是任务分片数量 在任务周期中含有一个split()阶段,在这个阶段做了两件事情: 通过配置项计算出建议的并发channel数量 执行reader插件中的的实际切片逻辑,并根据数量切分configuration,请注意,这一步计算出的数量可能小于第一步配置的并发数 所以在真正调度阶段,需要根据split()阶段中计算的两个值,计算出最终的channel数量 通过channel数量分配taskGroup 在计算出真正需要的channel数量之后,根据每个TaskGroup应该被分配任务的个数,计算TaskGroup的个数: 由上图可知,任务的分配是由JobAssignUtil去进行,而且从方法名称assignFairly也可以知晓,分配的逻辑是公平分配,使用的Round ...
DataX源码解析-整体架构
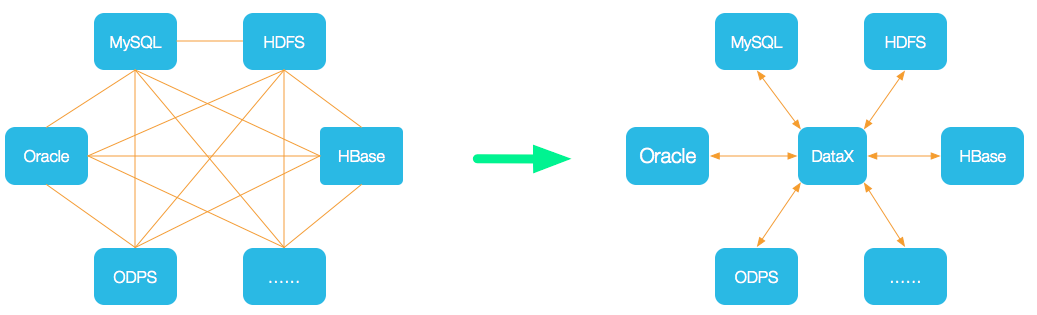
前言 近期在工作中需要用到DataX去作为公司内部的数据同步引擎,特花了一些时间研究了DataX的整体架构和设计思想,从中吸收了很多优秀的设计思路,作为一款纯Java实现的数据同步工具,相对于市面上已存在的基于大数据框架为背景的数据同步工具有着易部署、易扩展的优点,但不足的地方是alibaba只是开源了DataX单机模式代码,并未开源分布式部分代码,目前在Github中的只是阉割版是DataX,对此我表示很遗憾。 DataX简介 DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能,项目地址:https://github.com/alibaba/DataX 以上摘抄自DataX项目首页README 架构浅析 数据统一抽象 DataX作为一款高性能的 ...
数据结构系列32-插入排序
1234567891011121314151617181920212223242526272829303132333435363738394041/************************************************************************** File Name: insertSort.c* Author: TyrantLucifer* E-mail: TyrantLucifer@gmail.com* Blog: https://tyrantlucifer.com* Created Time: Sun 20 Mar 2022 08:32:01 PM CST ************************************************************************/#include <stdio.h>void printArray(int array[], int length) { for (int i = 0; i < length; i++) ...
数据结构系列31-哈希表
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253/************************************************************************** File Name: hashList.c* Author: TyrantLucifer* E-mail: TyrantLucifer@gmail.com* Blog: https://tyrantlucifer.com* Created Time: Sun 20 Mar 2022 12:28:03 AM CST ************************************************************************/#include <stdio.h>#include <stdlib.h>#define NUM 5typedef struct HashList &# ...

Apache Calcite 文档翻译 - 代数
代数 关系代数是Calcite的核心。每个查询都被表示为一棵关系运算符的树。你可以将一条SQL语句翻译为关系代数,也可以直接建立树状结构。 规则器规则使用保留语义的数学特性来转换表达树。例如,如果一个过滤操作没有引入其他输入的列,那么可以将一个过滤器下推至连接之前。 Calcite通过对关系表达式进行反复应用规划器规则来优化查询。一个成本模型指导了优化的整个过程,规划器生成一个替代的表达式,语义与之前表达式相同,但具有更低的成本。 规划过程是可扩展的。你可以添加自己的关系运算符、规划器规则、成本模型和统计数据。 代数构建 建立关系表达式的最简单方法时使用代数构建器RelBuilder,下面是一个示例: 表扫描 123456final FrameworkConfig config;final RelBuilder builder = RelBuilder.create(config);final RelNode node = builder .scan("EMP") .build();System.out.println(RelOptUtil.toString(n ...




