SparkCore源码分析之RDD默认分区规则
SparkCore源码分析之RDD默认分区规则
基础概念
RDD
定义
RDD,全称Resilient Distribute Dataset,学名弹性分布式数据集,是Spark框架中的基本数据抽象
特性
- A list of partitions,由一组分区组成
- A function for computing each split,计算切片逻辑
- A list of dependencies on other RDDs,rdd之前的相互依赖
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned),可选,对于键值对类型的rdd的分区规则
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file),可选,存储每个切片优先(preferred location)位置的列表
RDD创建
- 从集合创建
1 | val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) |
- 从文本文件创建
1 | val rdd: RDD[String] = sc.textFile("F:\\JavaProjects\\SparkCore\\input\\3.txt") |
从集合中创建RDD默认分区规则
分析默认分区数源码过程
- 查看
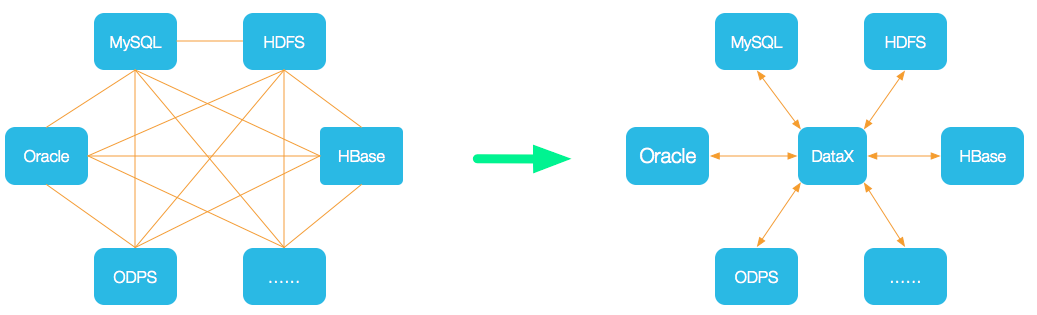
makeRDD源码,发现调用了parallelize方法,使用了从外面传进来的numSlices,如果创建rdd的时候没有指定默认分区数目,那么默认值为defaultParallelism=taskScheduler.defaultParallelism如图所示:
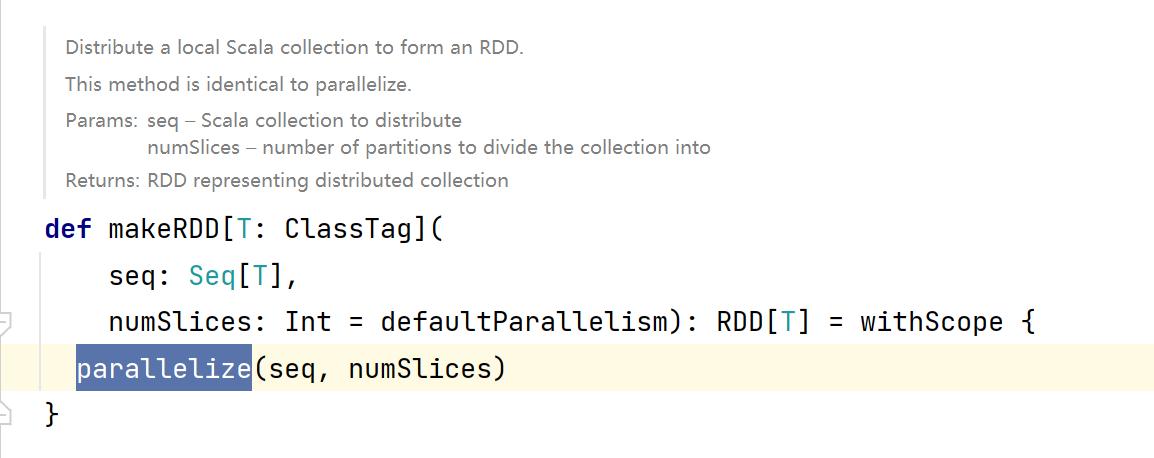

- 接着查看
taskScheduler.defaultParallelism源码,发现它这是一个特质,还有具体实现的子类,那么思路有了,去查看哪些类实现了这个特质:
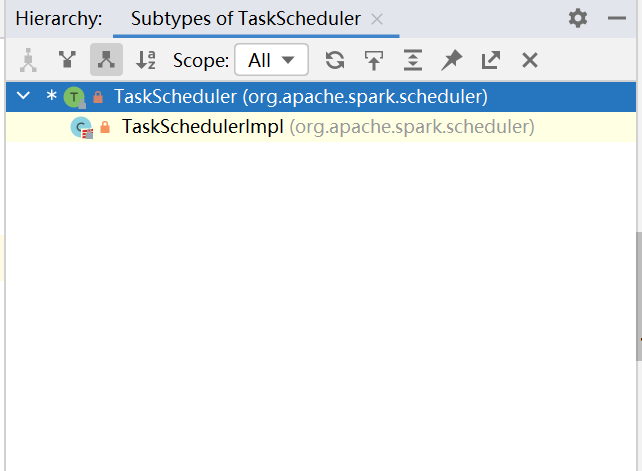
- 打开
TaskSchedulerlmpl,发现这依旧是一个特质的方法,看来还有一层特质需要去挖掘

- 再次查看实现了
defaultParallelism的子类,发现如下信息:
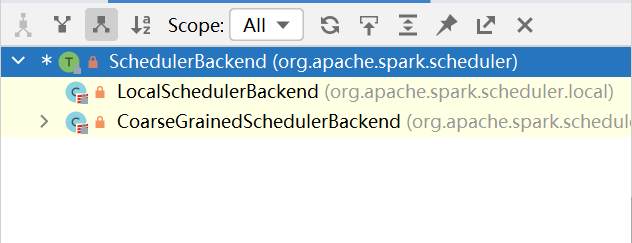
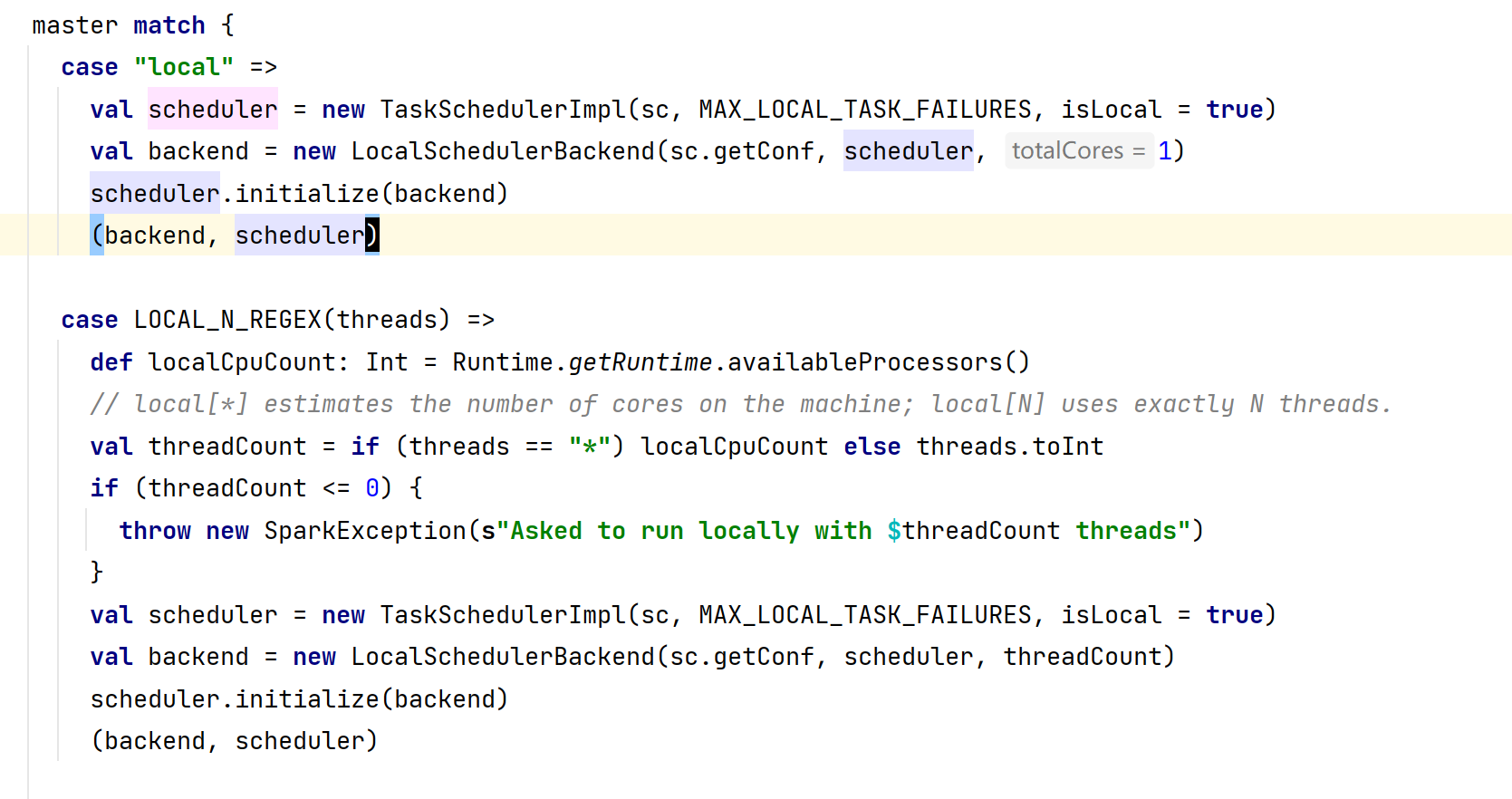
- 我们用的是本地Local模式进行测试,应该调用的是
LocalSchedulerBackend,接着去看LocalSchedulerBackend的具体方法实现,这里的conf应该是创建SparkContext时候新建的SparkConf类型的对象,如果设置了spark.default.parallelism这个属性的话,那么numSlices的值应该是这个属性的值,如果没有设置的话,值将是totalCores:

- 一般我们在SparkConf对象中是不会设置属性的,那么我接下来需要看看这个totalCores是怎么来的,此时发现它是作为一个入参传进来的,ok那我们需要去程序的入口去看一下这个值是怎么传进来的:
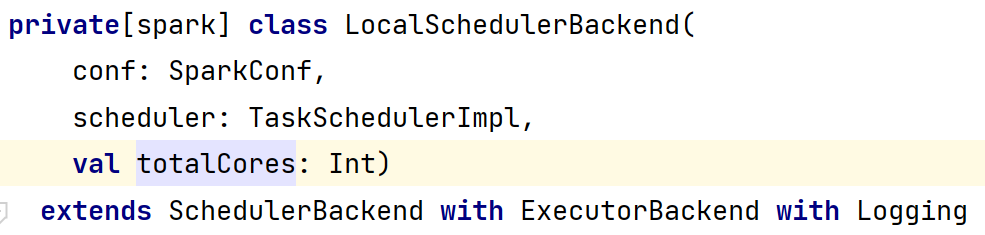
- 程序入口是SparkContext,所以需要在SparkContext.scala中搜索相关对象,此时发现模式匹配,感觉与真相更近了一步,在SparkConf中如果master设置为local的话,那么totalCores=1,如果master设置为local[1-9]|*,那么会有一个判断逻辑,local[*]会通过Runtime.getRuntime.availableProcessors()获取当前CPU可用核数并赋值给totalCores,local[1-9]会取1-9的值并赋值给totalCores:
分析默认分区规则源码过程
- 基于上面的基础,让我们从
parallelize方法开始:
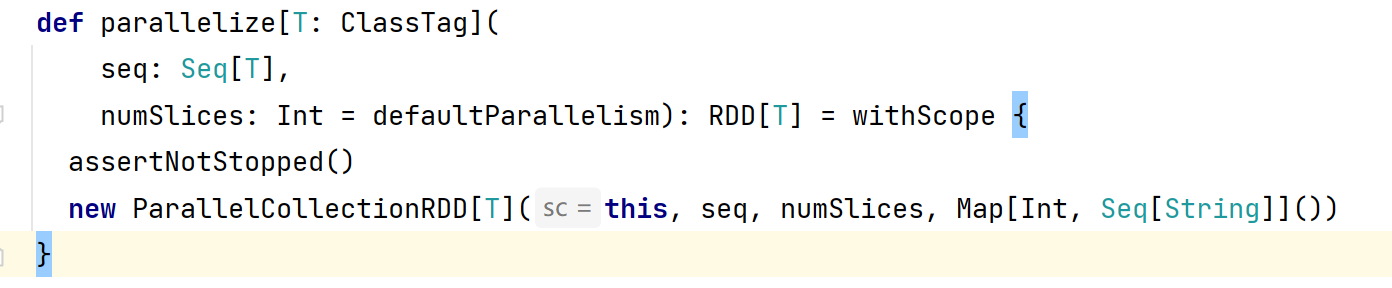
- 新建了
ParallelCollectionRDD对象,继续查看ParallelCollectionRDD,在对象中有一个slice方法,这个方法即是切片逻辑:
1 | def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = { |
仔细分析以上方法,发现我们的List在模式匹配中匹配到了_情况,所以核心逻辑在内层函数positions处封装:
1 | def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { |
length为集合的长度,numSlices为分区数,每一个分区的计算逻辑如下:
- start = (分区索引 * 集合长度) / 分区数
- end = ((分区索引 + 1) * 集合长度) / 分区数
即[start, end),前闭后开
举个简单例子,假设有一个集合List(1, 2, 3, 4),有3个分区,
那么分区和数据如下:
分区0:[0, 1) 1
分区1:[1, 2) 2
分区2:[2, 4) 3 4
总结
当从集合中创建rdd时,分区数如果不设置,那么默认分区数将遵循以下规则:
- 如果master为local,那么默认分区数为1
- 如果master为local[*],那么默认分区数为Runtime.getRuntime.availableProcessors(),即当前CPU可用核数
- 如果master为local[1-9],那么默认分区数为传进来的数字
默认分区切片逻辑如下:
- start = (分区索引 * 集合长度) / 分区数
- end = ((分区索引 + 1) * 集合长度) / 分区数
从文件中创建RDD默认分区规则
分析默认分区数源码过程
- 查看
textFile源码,我们发现分区参数不再是numSplices,而是minPartitions,从字面意义上都代表着这个参数代表了最小分区数,如果我们不传值的话,他默认还是defaultMinPartitions,接下来去看defaultMinPartitions:
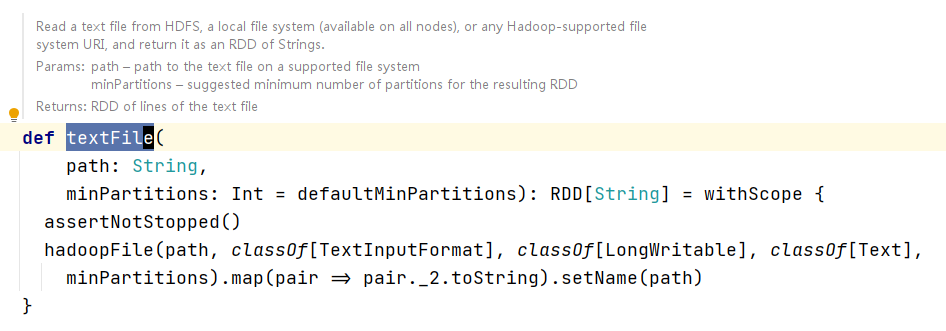

- 在
defaultMinPartitions中我们发现了熟悉的defalutParallelism,这不就是使用集合创建RDD时候的默认分区数嘛,比较逻辑就是这个数和2取小的
分析默认分区规则源码过程
- 查看
textFile源码,发现最终是新建了hadoopFile对象:
- 查看
hadoopFile源码,又发现底层新建了HadoopRDD,找到了RDD的子类,感觉靠谱一点:
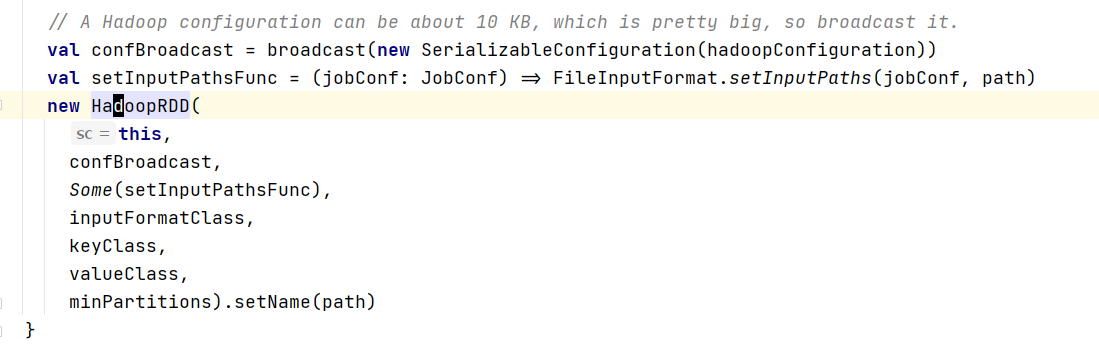
- 在RDD子类
HadoopRDD中我们找到所有RDD具有的特性,getPartitions方法:
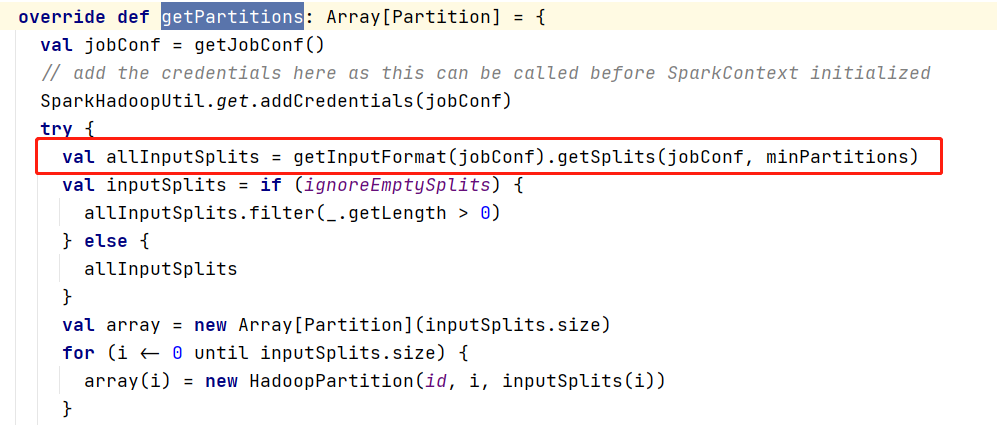
仔细一看,这不是hadoop MapReduce的文件切片代码吗?到底是不是呢?让我们一探究竟。
- 打开getSplits方法,果然跳转到了InputFormat.java,这时发现这是一个接口,我找一找他的子类吧:
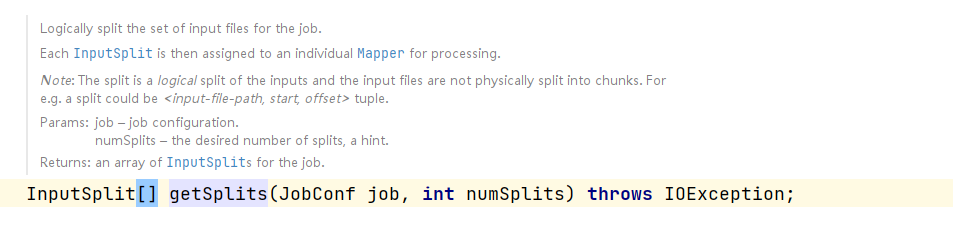

得来全不费工夫,发现了熟悉的FileInputFormat,来让我们看一下具体的实现逻辑:
1 | /** Splits files returned by {@link #listStatus(JobConf)} when |
首先有这么几个变量:
- totalSize:记录文件的字节数
- goalSize:计算目标分区一个区放多少字节数,计算逻辑 = totalSize / numSplits
- minSize:文件最小切片数,计算逻辑 = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize),这里minSplitSize是FileInputFormat写死的一个值1 - numSplits:分区数,也就是外面传进来的minPartitions
- splitSize:最终分区中需要包含多少字节数
核心就是splitSize的计算,计算逻辑 = Math.max(minSize, Math.min(goalSize, blockSize),blockSize就是块大小,hadoop3.x都是128M,在我们计算出这个每个切片需要读取的字节数大小之后,就开始进入了切片逻辑:
1 | long bytesRemaining = length; |
bytesRemaining就是我们整个文件的剩余字节数多少,初始状态下等于文件字节数,使用while循环除以splitSize的大小如果大于SPLIT_SLOP=1.1的话,可以切片,切片之后bytesRemaining进行自减:
切片索引为(0, splitSize),(splitSize, splitSize * 2),依次类推,最后切出来几个片,就是最终的分区数,此时需要注意,切片读取的时候是按照行读取的,所以有些分区的数据会发生丢失,举个例子:
1 | 0 1 2 3 4 5 6 7 |
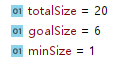
假设传进去minPartitions = 3,按照上面的逻辑进行计算splitSize = 6,那么一个切片应该放的字节数 = 6:
- 第一片:0 + 6,
a b c d e f - 第二片:6 + 6,
j h i j k,从第6个字节读到12个字节,由于是按行读取,13 - 16位的字节被第二片已经读掉了,导致第三片只是读到了p i u - 第三片:12 + 6,
p i u - 第四片:18 + 2,空
用程序打个断点看我们分析的是否正确:



总结
- 使用文件创建RDD集合时,如果不传minPartitions参数的话,默认是会取Math.min(集合创建RDD默认分区数,2),如果传了,文件字节数 % 最小分区数 = 0,那么分区数 = 最小分区数,如果不等于0,就需要先计算splitSize,然后再计算分区数,此时没有什么规律可言,
- 使用文件创建RDD集合时,切片规则根据hadoop的FileInputFormat的计算方式进行,想要切一片必须剩余字节数 / splitSize > 1.1
 wechat
wechat alipay
alipay